nosql-4-ds
NoSQL Databases 4 Data Science
Bases de Datos de Grafos - Neo4j
Mientras que para las BDs relacionales, cada registro es un ejemplo o instancia de una entidad, o una tabla, y las relaciones son solo llaves copiadas entre tablas, para las BDs de grafos lo que se almacena es la conexión o la relación entre 2 nodos.
Encima de esto, dado que cada nodo puede tener diferentes atributos, las bases de datos de grafos no tienen esquema, lo cual las vuelve un poco lentas para la escritura VS las BDs relacionales, sobre todo cuando llegamos al orden de millones de registros, debido a que cada nodo tendrá estructura diferente y no tenemos una estructura definida y fija como una tabla.
Otros ejemplos de BDs de grafos
- Amazon Neptune
- ArangoDB
- TerminusDB
El modelo de datos de una BD de grafos
Los componentes principales de una BD de grafos es:
- Nodos: los objetos principales en un diseño de grafos. Representan una entidad particular (una instancia de un objeto, o una instancia de un sustantivo - i.e. no representan un tipo de objeto o clase, sino el objeto en sí, no un tipo de marca_ropa_deportiva sino adidas, o Patagonia).
- Edges: la conexión entre 2 nodos. Representa una relación (un verbo) entre 2 objetos.
- Labels/Etiquetas: podemos usarlas para definir una clase o tipo de objeto y así agrupar nodos con características comunes.
- Propiedades: dentro de cada nodo o edge podemos tener un diccionario llave:valor con propiedades que califican a cada uno.
Modelo lógico de grafos
Supongamos la siguiente narrativa:
“Si, mira, quiero una red social mamalona, como facebook, pero que llamaremos “el libro de caras del bienestar” ya sabes? que nuestros datos no estén en servidores gringos neoliberales, sino en infraestructura 100% mexicana. Primero tendremos solamente Personas y Lugares, y cada Persona tendrá su nombre, lugar, género y correo electrónico; mientras que cada Lugar tendrá nombre, latitud y longitud. Las Personas estarán conectadas por una relación llamada Amistad, donde podemos tener años de amistad, y mientras que los Lugares estarán conectados a las Personas a través de la relación llamada Vive en, sin atributos, de momento.”
Cómo podemos representar esto?
- Nodos
Ustedes primero
- Edges
Ustedes primero
- Labels
Ustedes primero
- Propiedades
Ustedes primero
Ya podemos ver las diferencias entre los modelos relacionales y los de grafos.
Desde el punto de vista lógico, el modelo de grafos no promueve la generalización, es decir, el centrarnos en clases o entidades, sino en los ejemplos específicos de cada clase o entidad, sino que promueve la especialización. No nos importa que un Person viva en un Location, sino que Karl Marx vive en Alemania, y solo como conveniencia usamos la etiqueta Person para agrupar a Karl Marx junto a, a aunque se revuelque en su tumba, Adam Smith, Keynes, Miller, Modigliani, et al.
Modelo físico de grafos
Aparte de tener un nodo por cada Person, la diferencia más grande es al recorrer relaciones o edges.
La forma de registrar que 2 nodos están relacionados con un edge en bases de datos de grafos es utilizando apuntadores, esto es, direcciones de memoria que nos llevan de un lugar dentro de ella donde está un nodo, a otro lugar en la memoria donde está otro nodo.
Esto se le llama “Index-free Adjacency”. Esto es, no necesitamos un diccionario, ni una operación de intersección de conjuntos, ni un mapeo de columnas, como en los modelos relacionales, para poder ir de una tabla a otra.
En las BDs de grafos, las relaciones se encuentran ya físicamente en memoria, expresadas con el objeto de más bajo nivel que nuestra máquina puede utilizar. Esto implica que el recorrer un grafo para ir de nodo en nodo recolectando información, el performance NO DEPENDE DEL TAMAÑO DEL GRAFO! Podemos decir que tiene un running time linear de O(n), donde N es el num de edges a recorrer, que siempre será más reducido que la N involucrada en un JOIN.
En contraste, las BDs relacionales al viajar de una tabla a otra con JOIN, estamos utilizando una operación de intersección para ver en qué parte los 2 índices de las 2 llaves de la relación se traslapan, y por tanto su performance DISMINUYE A MEDIDA QUE HAY MÁS REGISTROS. Podemos decir que los JOIN tienen un running time de O(log n) cuando usamos llaves indexadas, y O(n^2) cuando son soft joins entre columnas que no son llaves o tienen índices.
Cuándo SÍ debemos usar una BD de grafos?
1. Cuando mis datos estén altamente conectados
Esto es, cuando el elemento central para nuestro análisis sea la conexión o la relación entre entidades particulares, y por tanto nuestros datos no sean transaccionales, entonces probablemente nos conviene una BD de grafos. Frecuentemente solo es necesario guardar los datos y realizar análisis sofisticado después.
2. Cuando la lectura sea más importante que la escritura
Si mi problema es transaccional en su naturaleza, y los analíticos que voy a ejecutar en estos datos con ayuda de JOIN no recorren la mayoría de las entidades, entonces quizá no requiera una BD de grafos.
3. Cuando mi modelo de datos cambie constantemente
Dado que las BDs de grafos no tienen esquema, al igual que las Document Databases, y por tanto para cada nodo o edge podemos agregar atributos a como deseemos, serán adecuadas cuando tengamos alto nivel de incertidumbre sobre la definición de nuestros datos, y a la postre nos permitirán que no todos los nodos tengan forzosamente valores en todos los atributos, y los que tengan, que no sean consistentes en cuanto a los tipos (i.e. el nodo “Adam Smith” tendrá el atributo tiene_sentido_del_humor en FALSE, mientras que el nodo “Milton Friedmann” lo tendrá en TRUE, y finalmente, el nodo “Karl Marx” lo tendrá en null).
Cuándo NO debemos usar una BD de grafos?
1. Cuando mis analíticos hagan table scan constantemente
Cuando los analíticos que vaya a correr sobre esos datos impliquen constantes table scans sean parciales o full, o secuenciales o con índices, entonces una BD de grafos puede que no sea la mejor opción.
2. Cuando mis búsquedas por ID sean constantes
Como vimos en nuestra intro a BDs columnares, los queries propios de una solución transaccional siempre obtienen todo el renglón, no se centran en relaciones, y frecuentemente buscarán un ID en toda la tabla. Esto es porque este tipo de queries no aprovecha el performance que dan las BDs de grafos para recorrer varios nodos.
3. Cuando debamos almacenar atributos de gran tamaño
Por ejemplo, si para un nodo hipotético “AMLO” debemos poner un atributo mañanera, y ahí debemos de colocar TODAS esas conferencias, resultará en un atributo de varios cientos de gigas. El precio de este almacenamiento es alto comparado con la capacidad de movernos y viajar a lo largo de nodos para recoger información.
⚠️ Ya se dieron cuenta? ⚠️
Ya se dieron cuenta que todas las BDs alternas a PostgreSQL están orientadas a analíticos?
Entonces hace todo el sentido del mundo que tengamos al frente de nuestra administración de datos una BD relacional para capturar TODO LO TRANSACCIONAL, y luego, dependiendo del tipo de analíticos que deseemos hacer, mover estos datos a una BD que propicie dicha actividad.
- Alimentar dashboards o modelos de ML: MonetDB o BDs columnares
- Redes de corrupción/fraude o investigaciones judiciales: Neo4j o BDs de grafos
- Visualización de actividad web o de APIs: MongoDB o BDs de documentos
Pero necesitamos un “buffer” intermedio para no cargarle la mano a ese PostgreSQL. Ese buffer intermedio es el Data Lake que veremos al rato 😉.
Instalando Neo4j en AWS EC2
Para esto usaremos sus cuentas de AWS Academy.
1. Entrar al Lab
Debió llegarles un correo de invitación a AWS Academy.
Esto los va a llevar a algo similar a Canvas.
⚠️ ESTE CANVAS NO TIENE NADA QUE VER CON EL CANVAS DEL ITAM, ES OTRO CANVAS TOTALMENTE DIFERENTE ⚠️
Una vez dentro van a ver esta pantalla:

Hay que dar click en Modules:

Y luego en Learner Lab - Foundational Services:

Y esperar a que cargue la terminal de nuestro ambiente.
En esta pantalla debemos de verificar que nuestra “instancia” del AWS Lab esté abajo. Lo sabemos por el “foquito rojo” arriba de la terminal:

Para arrancar nuestro lab, debemos dar click a Start Lab:

Después de unos buenos mins, tendremos esto:

Y estamos listos para levantar nuestra 1a EC2.
2. Levantar una EC2
Elastic Compute Cloud (EC2) de AWS son máquinas virtuales de diferentes tipos, PERO para el caso de AWS Academy, tenemos algunas restricciones.
Vamos a comenzar por abrir la AWS console dando click aquí:

Aquí ya vemos nuestras restricciones dentro de AWS Academy:
- Tenemos un usuario de AWS ya creado: el usr
voclabs/userXXXXXXX=[Nombre] @ XXXX-XXXX-XXXX. Esto no lo podemos cambiar, ni nos conviene hacerlo. - Podemos ver que la región por default es
N. Virginia. Esto tampoco nos conviene cambiarlo. AWS tiene varios data centers en bunkers debajo de los cerros o la tierra para mayor seguridad, porque saben que, literal, el internet corre sobre AWS. Uno de estos bunkers está en North Virginia, y es donde AWS Academy nos dejará levantar recursos y servicios. Fuera de esa región, los servicios de AWS para Academy no están disponibles.

Accedamos ahora a la consola de EC2 dando click aquí:

Contrario a una cuenta normalita de AWS, para poder cumplir con las restricciones de AWS Academy, debemos crear la máquina virtual primero seleccionando una AMI (imagen o template) ya existente:

Seleccionamos Public Images

Vamos a filtrar las AMIs con los criterios: 1) que sean AMIs pertenecientes a Amazon, y 2) que se llamen “Cloud9”:
https://user-images.githubusercontent.com/1316464/138736396-89262074-792d-4e1b-ad3c-5c3062338496.mp4
Vamos a ordernar la lista de AMIs por nombre y de manera descendente para poder tomar la AMI más reciente:
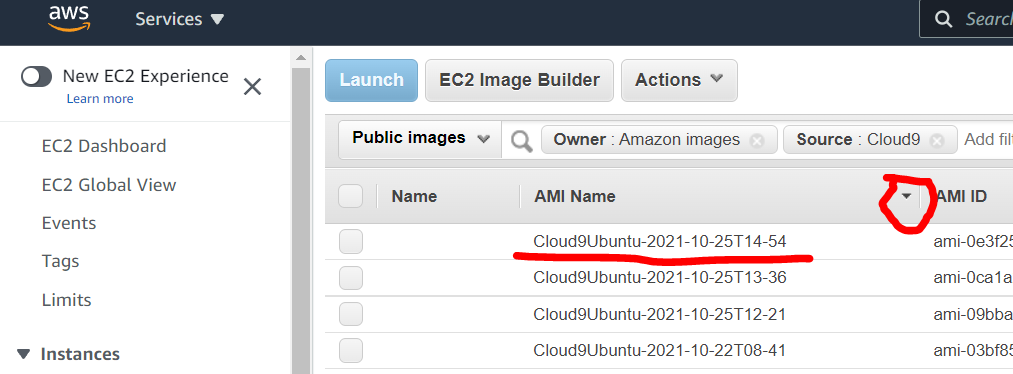
Y vamos a dar click en Launch:

Vamos a definir la siguiente configuración con ayuda del otro video en donde introdujimos cloud computing:
- Instancia tipo t2.micro
- 10GB de storage de General Purpose SSD
- Security group: Servicios SSH, HTTP, HTTPS. Puertos 50000, 5432, 5433, 7474, 7473, 7687, 27017
Cuando lleguemos a la parte de llaves de acceso, vamos a seleccionar la llave que viene por default en nuestra cuenta de AWS administrada por Academy:
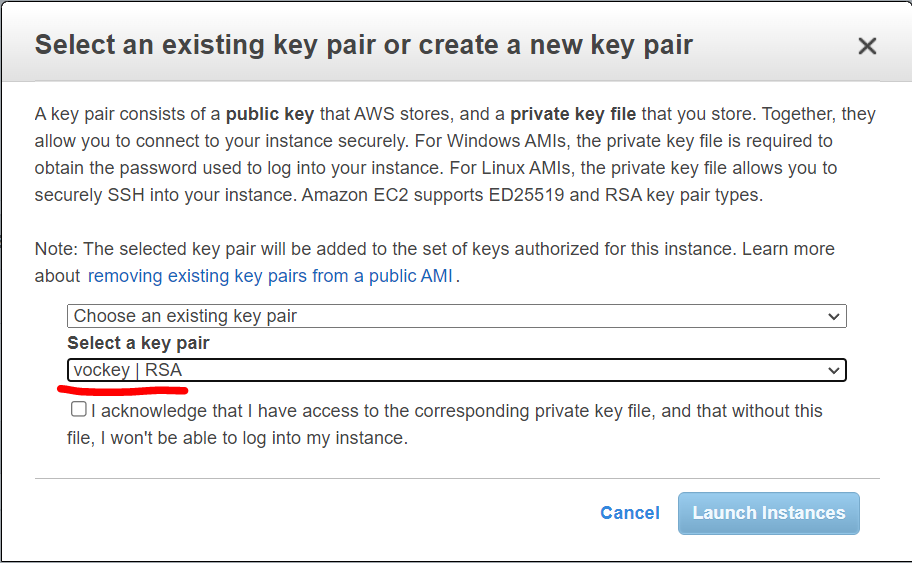
Y finalmente dar click en Launch Instances.
Para acceder a la instancia, vamos a usar una terminal de Ubuntu. Primero necesitamos ver la ventana de detalles de AWS de regreso en nuestro Lab:

Luego dar click en Download PEM:

Ya con la llave PEM descargada, tenemos que hacer lo siguiente para entrar a la instancia:
$ cp /mnt/c/Users/ramos/Downloads/labsuser.pem .
$ chmod 600 labsuser.pem
$ ssh -i "labsuser.pem" ubuntu@3.86.144.108
La IP de la instancia la obtenemos así:
https://user-images.githubusercontent.com/1316464/138751707-edbb6931-c056-45b9-807f-3481043b392f.mp4
Instalar Neo4j
Ejecutamos los siguientes comandos en la terminal:
sudo add-apt-repository -y ppa:openjdk-r/ppa
sudo apt-get update
wget -O - https://debian.neo4j.com/neotechnology.gpg.key | sudo apt-key add -
echo 'deb https://debian.neo4j.com stable latest' | sudo tee -a /etc/apt/sources.list.d/neo4j.list
sudo add-apt-repository universe
sudo apt-get update
Qué estamos haciendo aquí?
- agregando un nuevo repo a la lista de fuentes autorizadas por Ubuntu para descargar paquetes
- actualizando para comprobar que llegamos a esa fuente nueva
- bajando la llave privada del repo de Neo4j
- comprobando que esta llave es válida para el nuevo repo de paquetes
- agregando el repo “universe” donde están paquetes de versiones anteriores de utilerías de linux
- actualizando accesos
Una vez hecho esto, vamos validar si los paquetes de Neo4j están disponibles para Ubuntu:
apt list -a neo4j
La salida debe ser:
Listing... Done
neo4j/stable 1:4.3.6 all
neo4j/stable 1:4.3.5 all
neo4j/stable 1:4.3.4 all
neo4j/stable 1:4.3.3 all
neo4j/stable 1:4.3.2 all
neo4j/stable 1:4.3.1 all
neo4j/stable 1:4.3.0 all
Finalmente, podemos instalar Neo4j:
sudo apt-get install neo4j=1:4.3.6
Para arrancar el server de Neo4j debemos primero asignar un password a nuestro usuario ubuntu:
sudo passwd
Enter new UNIX password: XXXXX
Retype new UNIX password: XXXXX
passwd: password updated successfully
Y luego vamos a habilitar el servicio con los siguientes comandos:
sudo systemctl enable neo4j
Synchronizing state of neo4j.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable neo4j
Y con esto ya podemos arrancar el server:
$ sudo systemctl start neo4j
Conectándonos a Neo4j
Antes de conectarnos debemos modificar el archivo /etc/neo4j/neo4j.conf para que Neo4j acepte conexiones de todo el mundo 🌐:
nano /etc/neo4j/neo4j.conf
Hay que buscar la siguiente línea y descomentarla (quitarle el #):
#dbms.default_listen_address=0.0.0.0
Y reiniciar el server
sudo systemctl restart neo4j
Ahora si, conectémonos a Neo4j.
Vamos a abrir un browser y entrar a https://[IP ADDRESS]:7474. Nos va a pedir user y password. Los de default son neo4j/neo4j, pero en cuanto los usemos, Neo4j nos va a pedir que los cambiemos.
Lo que responde en el puerto 7474 es solamente un cliente ligero web hacia Neo4j, no el Neo4j como tal.
Ese responde en el 7687, a través de un servidorsito de conexiones llamado Bolt, con el URL jdbc:neo4j:bolt://[IP ADDRESS]:7687/.
Cargando la versión de grafos de Northwind
Los cuates de Neo4j hicieron una versión de grafos de Neo4j. No tiene todas las tablas, pero es suficiente para contrastar los paradigas relacionales y de grafos.

Vamos a establecer algunas similitudes con SQL antes de continuar:
Similitudes con SQL
- Un registro es un Node
- El nombre de una tabla es un Label
- Un
joinoforeign keyes un edge o relationship
En particular, al tratarse de la BD de Northwind:
- Cada registro de la tabla
ordersen la BD de Northwind se vuelve un Node con LabelOrderen nuestro modelo de grafos- Y así sucesivamente con el resto de las tablas
- El
joinentresuppliersyproductsse convierte en un edge o relationship llamadoSUPPLIES(unsupplierSUPPLIESNproducts), y así sucesivamente con otras tablas, salvo los siguientes casos especiales: - El
joinrecursivo entreemployeesyemployeesse convierte en un edge con el nombreREPORTS_TO. - La tabla intermedia
order_detailsque soporta la relación N:M entreproductsyordersdesaparece y se convierte en un edge o relationship llamadoCONTAINSy con atributosunitPrice,quantity,discount.
Neo4j está construido casi en su totalidad en Java, por lo que ver este camelCaseEnLosAtributos no es extraño, como tampoco lo es que los nombres de los Labels estén en mayúscula, porque su análogo en grafos son Clases, y sabemos que las clases en Java van con mayúscula inicial.
De esta forma, tenemos el siguiente diagrama de grafos que representa nuestra BD de Northwind:

Diferencias con SQL
- No hay nulos! Un nulo, al ser la ausencia de algo, es simplemente la ausencia del atributo, o del node o de un edge.
- Dada la “Index-free Adjacency”, sabemos qué nodes tienen particular relationship con otro node, en lugar de hacer un
joiny realizar la búsqueda de overlap entre 1 llave primaria de una tabla y la llave foránea de otra tabla. - Aunque puede haber normalización justo como en el modelo E-R, ésta no es forzosa ni rígida, y consiste principalmente en convertir attributes en nodes, aunque al hacer esto debemos tener en mente que al convertir, los nodes son instancias particulares, no clases ni Labels.
Ahora si, la carga.
Para cargarla vamos a utilizar el lenguaje Cypher, que es como el SQL para Neo4j.
- Products
LOAD CSV WITH HEADERS FROM "http://data.neo4j.com/northwind/products.csv" AS row
CREATE (n:Product)
SET n = row,
n.unitPrice = toFloat(row.unitPrice),
n.unitsInStock = toInteger(row.unitsInStock), n.unitsOnOrder = toInteger(row.unitsOnOrder),
n.reorderLevel = toInteger(row.reorderLevel), n.discontinued = (row.discontinued <> "0")
Qué estamos haciendo aquí?
Al igual que SQL, Cypher es un 4th generation language, que en simples términos significa que se parece muchísimo a como se estructuran órdenes y declaraciones en inglés.
LOAD CSV: el comando de CypherLOADes similar alCOPYde PostgreSQL y MonetDB. La parte deWITH HEADERS, al igual que elCOPYen PostgreSQL indica que el CSV a cargar tiene los nombres de las columnas en el 1er renglón. El keywordFROMes para indicar la fuente, y afortunadamente para nosotros, Cypher acepta URLs aquí, por lo que no es necesario descargar los CSVs a nuestro storage local y solo jalarlos del internet.CREATE (n:Product)crea el nodencon el labelProduct. Aquí vale la pena que cubramos unos aspectos de la sintaxis de Cypher:- Un node es representado por dos paréntesis, a manera de “bolita”. El node
nlo representamos como(n). Por ejemplo:create (tonyStark:SuperHero {group:'Avengers'} - Un edge es representado por una flechita como esta
-[:LABEL]->y obviamente debe conectar 2 nodes. elLABELes igualito a los labels que califican a los nodes, como sigue:create (tonyStark)-[:MENTORS]->(peterParker)-[:WORKSFOR]->(jjJameson) - Las properties de un node se fijan con
{}acompañando a los nodes, como sigue:CREATE (tonyStark:SuperHero {group: 'Avengers'}) - Igual, las properties de un edge se fijan con
{}, así:create (tonyStark)-[:MENTORS {since:2017}]->(peterParker)-[:WORKSFOR {at:'Daily Bugle'}]->(jjJameson) - Las properties, sean de un edge o de un node pueden ser arrays:
(tonyStark:SuperHero {suits:['Mark IV', 'Mark V']})-[HOLDS {on:['Glove','Avengers Compound']}]->(soulStone:INFINITY_STONE) - Es buena práctica primero crear los nodes, luego los edges.
- Un node es representado por dos paréntesis, a manera de “bolita”. El node
SET n = rowestá indicando que al crear los nodos con la variablen, haga una equivalencia entre esa variable y el renglón del archivo CSV que estamos cargando.n.unitPricey demás comandos están preprocesando los datos del archivo CSV para poder guardarlos de forma correcta.toIntegerestá transformando a entero, mientras quen.discontinuedse está evaluando a la expresiónrow.discontinued <> "0".- 👀 OJO 👀: esto nos indica que durante la lectura la mayoría de los campos se están importando como strings.
- 👀 OJO #2 👀: la comparación
<> "0"no es válida en Java, pero si lo es en Javascript. Neo4j está hecho en Java por debajo, pero tiene un preprocessor de LISP, que es la base de Javascript, que si entiende esta expresión.
Vamos a ejecutar este import en DBeaver.

Y dónde están las tablas?!

Vamos a abrir el cliente de Neo4J apuntando nuestro browser a http://3.95.241.22:7474/
Veremos que ahí están nuestros 25 productos:

Fijémonos en la cajita de texto de arriba:

En esta caja vamos a poder escribir queries en “Cypher”. Qué está haciendo este query? MATCH (n:Product) RETURN n LIMIT 25.
MATCHes parecido que elFROM.- La expresión
n:Productva a buscar los nodes que tengan el labelProduct. RETURN nes como la parte delSELECTdonde indicamos las columnas que queremos obtener; en este caso, queremos los nodos, pero bien pudieramos obtenern.discontinuied, on.reorderLevel, es decir, atributos del (o los) nodo(s) que han hecho match.
Vamos a cargar el resto de la BD:
Categories
LOAD CSV WITH HEADERS FROM "http://data.neo4j.com/northwind/categories.csv" AS row
CREATE (n:Category)
SET n = row
Suppliers
LOAD CSV WITH HEADERS FROM "http://data.neo4j.com/northwind/suppliers.csv" AS row
CREATE (n:Supplier)
SET n = row
Una vez creados, nuestra BD se ve así:

Esto lo sacamos con MATCH (n) RETURN n, que es como un SELECT * pero recursivo a todas las tablas.
⚠️ Faltan las relaciones! ⚠️
Vamos a crear los edges que van desde Product a Category:
MATCH (p:Product),(c:Category)
WHERE p.categoryID = c.categoryID
CREATE (p)-[:PART_OF]->(c)
Qué estamos haciendo aquì?
- Estamos buscando todos los nodos que tengan el label
Producty los que tengan el labelCategory, y los estamos poniendo en las variablespyc, respectivamente. - Estamos agregando una condición que se parece muuuuuuucho al
JOINde SQL. Esto es para poder ejecutar la siguiente parte: - Estamos creando un edge con label
PART_OFentrepyc.
Ahora vamos a crear los edges para relacionar Product y Supplier:
MATCH (p:Product),(s:Supplier)
WHERE p.supplierID = s.supplierID
CREATE (s)-[:SUPPLIES]->(p)
Misma estructura que el comando anterior.
Después de todo esto, cómo se ve nuestra BD?

Vemos que se han formado 2 “comunidades”: los productos lácteos, y los no-lácteos. De esto podemos deducir que los productos lácteos tienen un grupo de suppliers que no suministran otro tipo de productos, mientras que los no-lácteos son suministrados por el resto de los proveedores.
Las comunidades son grupos de nodes que están conectados por sus relaciones, pero que no están conectados a otro conjunto de nodes. Son importantes en el análisis de grafos para elaborar hipótesis o realizar investigaciones.
Vamos a lanzar los siguientes queries:
1. Qué categorías nos vende cada proveedor?
MATCH (s:Supplier)-->(:Product)-->(c:Category)
RETURN s.companyName as Company, collect(distinct c.categoryName) as Categories
Qué estamos haciendo aquí?
MATCH- más formalmente, este comando busca un patrón dentro de nuestro grafo. En este caso, está buscando las rutas, de cualquier label, entreSupplier,ProductyCateogory.- La ausencia de label en los edges indica que no nos importa la etiqueta de la relación, solo que exista.
- Estamos asignando los nodos de las etiquetas
SupplieryCategorya las variablessyc, respectivamente. Dado que para responder la pregunta, NO NOS INTERESAN losProduct, no le estamos asignando variable, porque no nos vamos a referir a ellos, solo necesitamos sus relaciones.
RETURN s.companyName as Companyes self-explanatory, no?collect(distinct c.categoryName) as Categorieses una función de agregación similar acount()oavg()en SQL. Esta función recolecta los resultados y los mete en una lista (entre[]).- Qué pasa si no ponemos el
distinct? Y si no usamos elcollect()?
- Qué pasa si no ponemos el
2. Qué proveedores nos venden frutas y verduras?
MATCH (c:Category {categoryName:"Produce"})<--(:Product)<--(s:Supplier)
RETURN DISTINCT s.companyName as ProduceSuppliers
Qué estamos haciendo aquí?
- Estamos buscando los nodes con label
Categorycuyo attributecategoryNamesea “Produce” (noten las doble comillas), y sus relaciones conProductySupplier, de nuevo sin importar el label de dichas relaciones. RETURN DISTINCT s.companyName as ProduceSuppliersregresa el attributecompanyNamede los nodos elegidos en elMATCH.
Cargar el resto de la BD:
Customers
LOAD CSV WITH HEADERS FROM "http://data.neo4j.com/northwind/customers.csv" AS row
CREATE (n:Customer)
SET n = row
Orders
LOAD CSV WITH HEADERS FROM "http://data.neo4j.com/northwind/orders.csv" AS row
CREATE (n:Order)
SET n = row
Relación Customers -> Orders
MATCH (c:Customer),(o:Order)
WHERE c.customerID = o.customerID
CREATE (c)-[:PURCHASED]->(o)
Relación Order -> Product
Esto era en PostgreSQL la tabla intermedia order_details pero en grafos NO NECESITAMOS tablas intermedias para expresar relaciones N a M!
LOAD CSV WITH HEADERS FROM "http://data.neo4j.com/northwind/order-details.csv" AS row
MATCH (p:Product), (o:Order)
WHERE p.productID = row.productID AND o.orderID = row.orderID
CREATE (o)-[details:ORDERS]->(p)
SET details = row,
details.quantity = toInteger(row.quantity)
Vamos a tener el siguiente grafo:

Podemos ver que al menos en esta versión de Northwind, tenemos bastantes clientes que nunca nos han pedido, pero esto no es una comunidad, porque no hay ninguna conexión entre estos. Tienen cosas en común, pero ninguna relación, por lo que no podemos decir que es una comunidad.
Ejercicios del semestre pasado…ahora en Neo4j
Cuál es la orden más reciente por cliente?
En SQL:
select max(o.order_date), o.order_id , o.customer_id
from orders o
group by o.customer_id;
En Cypher
match (c:Customer)-[:PURCHASED]->(o:Order)
return c.contactName as name, max(o.orderDate) as max_ord_date
order by name
De nuestros clientes, qué función desempeñan y cuántos son?
select c.contact_title , count(c.contact_title) conteo
from customers c
group by c.contact_title
order by conteo desc;
match (c:Customer)
return c.contactTitle as title, count(c.contactTitle) as title_count
order by title
Cuántos productos tenemos de cada categoría?
select c.category_name, count(c.category_name)
from categories c join products p on c.category_id =p.category_id
group by c.category_name;
match (c:Category)<-[:PART_OF]-(p:Product)
return c.categoryName as name, count(c.categoryName) as name_count
order by name
Cómo podemos generar el reporte de reorder?
select product_id, product_name, units_in_stock, reorder_level
from products p
where (units_in_stock<reorder_level);
match (p:Product)
where p.unitsInStock < p.reorderLevel
return p.productName as prod_name, p.unitsInStock as units_stock, p.reorderLevel as reord_level
order by units_stock
A donde va nuestro envío más voluminoso?
La respuesta más correcta en SQL:
with summary as (
select o.order_id as ord_id , o.ship_country as shp_ctry, sum(od.quantity) as sum_qty
from orders o join order_details od using (order_id)
join products p using (product_id)
group by o.order_id , o.ship_country
)
select ord_id, shp_ctry , max(sum_qty) as max_qty
from summary
group by ord_id, shp_ctry
order by max_qty desc;
Con order.freight (otra respuesta correcta en SQL):
match (o:Order)
return o.shipCountry as ship_country, max(toFloat(o.freight)) as max_freight
order by max_freight desc
Con order_details.quantity (respuesta incorrecta, pero la ponemos aquí para respetar el replicado en Cypher de respuestas en SQL)
match (o:Order)-[od:ORDERS]->(p:Product)
return o.shipCountry as ship_ctry, max(od.quantity) as max_qty
order by max_qty desc
TBD: Exporar responder esta pregunta con la suma de quantities de todas las ordenes de un país, y luego sacar el max
call {
match (o:Order)-[od:ORDERS]->(p:Product)
return o.orderID as ord_id,
o.shipCountry as ship_country,
sum(od.quantity) as sum_qty_per_order
order by sum_qty_per_order desc
}
return ship_country, max(sum_qty_per_order)
Veamos que el comando call se parece algo a los common table expressions de SQL.
Qué productos mandamos en navidad?
En SQL
select p.product_name
from products p join order_details od on p.product_id =od.product_id
join orders o on od.order_id = o.order_id
where extract(month from o.shipped_date) = 12 and extract(day from o.shipped_date) = 25;
En Cypher
match (o:Order)-[od:ORDERS]->(p:Product)
where apoc.date.field(apoc.date.parse(o.orderDate), 'month') = 12 and apoc.date.field(apoc.date.parse(o.orderDate), 'd') = 25
return o.orderID, o.orderDate, collect(p.productName)
OJO! Debemos instalar la librería APOC para poder correr las funciones de arriba.
apoc.date.field es similar al extract([day|month|year|hour|second] from date)
apoc.date.parse() es similar a date([string representando date])
La instalación de APOC es como sigue:
- Entrar a la máquina virtual de EC2 en donde tenemos el Neo4j con
ssh -i labsuser.pem ubuntu@[LA IP DE SU MÁQUINA] - Entrar el comando
wget https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/download/4.3.0.3/apoc-4.3.0.3-all.jar- esto va a descargar la librería - Debemos copiar esta librería a
/var/lib/neo4j/plugins/con el comandocp apoc-4.3.0.3-all.jar /var/lib/neo4j/plugins/ - Ahora debemos reiniciar el Neo4j con el comando
sudo systemctl restart neo4j.service
Con eso ya debemos tener acceso a las funciones de APOC.
Cuál es el promedio de flete gastado para enviar productos de un proveedor a un cliente?
En SQL
select c.company_name as customer, s.company_name as shipper, avg(o.freight) as flete
from orders o join shippers s on (o.ship_via = s.shipper_id)
join order_details od on (od.order_id = o.order_id)
join customers c on (c.customer_id = o.customer_id)
group by c.company_name, s.company_name;
En Cypher
match (c:Customer)-[pr:PURCHASED]->(o:Order)-[od:ORDERS]->(p:Product)<-[sp:SUPPLIES]-(s:Supplier)
return c.companyName as cust_name, s.companyName as supp_name, avg(toFloat(o.freight)) as avg_freight
order by cust_name
Carga de los Pandora Papers en Neo4j
Los Pandora Papers son documentos de constitución y quiebra de empresas, transferencias millonarias y cambios de board que, como los Panama Papers en su momento, han develado las obscenas fortunas de muchísima gente poderosa: deportistas, políticos, personas de negocios, realeza, políticos y celebridades, y peor de todo, como evitan ser gravados por sus paises de residencia.
Es la opinión de este profesor que ser rico no es malo, y que la recaudación mediante mecanismos de gravamen de riqueza frecuentemente se usan en programas clientelares o no se usan en el interés verdadero de los ciudadanos.
Pero evadir el fisco si es ilegal, y da pie a otras actividades ilegales como lavado de dinero, lo cual habilita redes criminales como narcotráfico, trata, prostitución, etc.
Encima de esto, estos offshore leaks muestran algo que raya en lo inmoral. En medio de la pandemia de COVID19, cuando millones de personas están atravesando por una crisis económica que está ampliando la brecha entre los menos afortunados, y cuando cientos de gobiernos están experimentando una recuperación anémica, por decir lo menos, esconder fortunas para que no sean gravadas, es decir, para no compartir con la población ni contribuir al fisco, es, por definición, malvado.
Neo4j puso a disposición del International Consortium of Investigative Journalists no solo licencias empresariales de su BD de Grafos, sino infraestructura, servers, graph visualizers, y todo el resto de sus productos for free para que el ICIJ hiciera su chamba.
El resultado de los Panama Papers a 2019:
- Investigaciones de la policía fiscal en 82 paises (incluído MX)
- La firma que habilitó todo este desmadre, Mossack Fonseca, fue desmantelada y sus dueños a la cárcel (aunque solo por meses y sus assets personales no fueron incautados).
- Hay una película buenísima en Netflix de este escandalazo: The Laundromat
- Nueva Zelanda, Alemania, UK y otros reformaron su miscelánea fiscal para incrementar vigilancia e incentivar disclosure de hidden assets
- Renuncia de políticos en Mongolia, Pakistán, España, Islandia (donde renunció la cabeza de gobierno) y otros.
- $1,200 mdd recuperados por agencias de revenue nacionales a nivel global
En México hubo 33 personalidades entre deporitistas, artistas y políticos implicados en el leak:
- La actriz Edith González a través de su esposo Lorenzo Margain
- Salinas Pliego abrió 9 empresas en Nueva Zelanda para comprar 1 yate y 1 cuadro de Goya
- Juan Armando Hinojosa, el constructor preferido en el sexenio de EPN, creo a través de Mossack Fonseca 4 empresas offshore para esconder dinero proveniente de contratos de adjudicación directa por $2,800 mdd y a cambio, otorgar regalos a la pareja presidencial
Y las consecuencias seguirán, sobre todo alimentadas por otros leaks. La tecnología de Neo4j por fin ha puesto a los prosecutors pasos adelante de los offenders.
Preparación de la carga
La versión de Neo4j Community, que es la que estamos usando y es gratuita, SOLO PUEDE TENER 1 BD!

Entonces vamos a tener que crear OOOOOTRA instancia de EC2 para VOLVER a instalar Neo4j y poder hacer este ejercicio :/
Es una BD grande, por lo que primero tenemos que hacer unas modificaciones a la config de Neo4j:
-
Cambiar el directorio de default para importar archivotes. Esto lo logramos comentando la línea
#dbms.directories.import=/var/lib/neo4j/importdel archivo/etc/neo4j/neo4j.conf. Es un archivo de sistema, por lo que hay que editarlo consudo nano /etc/neo4j/neo4j.conf. -
Igual editar el archivo
/etc/security/limits.confconsudo nano /etc/security/limits.confy agregar hasta el final los siguientes 2 registros para poder abrir archivos grandes desde el filesystem de Ubuntu:
root soft nofile 40000
root hard nofile 40000
-
Finalmente, en los archivos
/etc/pam.d/common-sessiony/etc/pam.d/common-session-noninteractiveagregarsession required pam_limits.so. -
Vamos a instalar la librería APOC como lo vimos en uno de los ejercicios aquí:
-
Vamos a usar el siguiente gist de Github: https://gist.github.com/rvanbruggen/00d259a453de13106091e2d507c2d86c, ejecutando sección por sección. Estas secciones van a resultar en el siguiente esquema, que podemos obtener ejecutando
call db.schema.visualizationen la consola web de Neo4j.

Explorando los Pandora Papers
- Cuántas jurisdicciones hay entre todas las entidades?
MATCH (n:Entity)
RETURN distinct n.jurisdiction, count(n);
- Qué entidades hay en la jurisdicción más “popular”?
MATCH (o:Officer)-[rel]->(e:Entity)
WHERE e.jurisdiction CONTAINS “British Virgin Islands”
RETURN o, rel, e;
- De las entidades, cuáles son proveedoras y cuales son las más usadas?
MATCH (e:Entity) return e.provider, count(*) as c order by c desc;
- Cuantos oficiales (shareholder, director, representante legal, etc) de un país están asociados con entidades de los paraísos fiscales?
MATCH (c1:Country)<--(o:Officer)-->(e:Entity)--(c2:Country)
WITH distinct c1.name as OfficerCountry, c2.name as EntityCountry, count(*) as PatternFrequency
WHERE PatternFrequency >= 5
RETURN OfficerCountry, EntityCountry, PatternFrequency
ORDER BY PatternFrequency desc;
- Mostrar el grafo de la familia Aliyev de Azerbaijan
Esta familia es de interés por su actual patriarca, Ilham Aliyev, “presidente” (en realidad, dictadorsillo) de Azerbaiján y ganador 2012 del premio a la persona más corrupta por el Organized Crime and Corruption Project.

Su familia controla TODA la actividad económica del país, y con ayuda de cuentas offshore y paraísos fiscales han logrado lavar o esconder una fortuna multimillonaria proveniente del petróleo.
MATCH (o:Officer)-->(e:Entity)
WHERE toLower(o.name) CONTAINS 'aliyev'
RETURN *;
Análisis avanzado de grafos
Con ayuda de la librería Neo4j Graph Data Science podemos realizar análisis más avanzados de los Pandora Papers.
Instalación de GDS
https://s3-eu-west-1.amazonaws.com/com.neo4j.graphalgorithms.dist/graph-data-science/neo4j-graph-data-science-1.7.2-standalone.zipunzip neo4j-graph-data-science-1.7.2-standalone.zipsudo cp neo4j-graph-data-science-1.7.2.jar /var/lib/neo4j/plugins/- Modificar el archivo
/etc/neo4j/neo4j.confconsudo nano /etc/neo4j/neo4j.confy agregar la líneadbms.security.procedures.unrestricted=gds.* - Y la línea
dbms.security.procedures.allowlist=apoc.coll.*,apoc.load.*,gds.*- probablemente ya está si ya instalaron APOC. - Reiniciar Neo4j con
sudo systemctl restart neo4j.service
Centralidad con Page Rank
Page Rank fue el 1er algoritmo de búsqueda de Google. Forma parte de un grupito de algoritmos muy, muy, muy poderosos pero también muy, muy, muy subestimados fuera de “clasificación” y “regresión” llamados information retrieval, y mide la importancia de cada nodo en el grafo ponderando el número de edges que entran a cada uno, porque “una página es solo tan importante como las otras páginas que ligan a ella”.
Similar a la muy perversa métrica de producción científica de que un paper es más importante entre más sea citado.

Si visualizamos todo nuestro grafo de Pandora Papers, vemos que, evidentemente, las British Virgin Islands es el nodo central, sin el cual el grafo simplemente no existiría:

Pero qué tal las entities?
El algoritmo Page Rank de Neo4j funciona de la siguiente forma:
- Primero debemos de crear una proyección de nodos y relaciones, parecido a lo que hacíamos en MongoDB, donde preseleccionabamos un conjunto de atributos y documentos, así en Neo4j tenemos que seleccionar un conjunto de nodes y edges para delimitar y dar contexto a nuestro análisis. En este caso, con la función
gds.graph.create()proyectaremos los nodosEntityyOfficer, y la relación entre ellos[OFFICER_OF], y guardaremos esa proyección en la variableentitiesAndOfficers:
call gds.graph.project(
'entitiesAndOfficers',
['Entity', 'Officer'],
['OFFICER_OF']
)
YIELD
graphName AS graph, nodeProjection, nodeCount AS nodes, relationshipCount AS rels
- Enviaremos ahora esta proyección al algoritmo
PageRankde esta forma:
CALL gds.pageRank.stream('entitiesAndOfficers')
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS name, score
ORDER BY score DESC, name ASC
En este comando, YIELD es el keyword con el que extraemos info de la tabla de resultados, mientras que RETURN sirve igual como from de SQL pero tomando como base lo contenido en YIELD y el grafo de entrada.
El resultado es:
| name | score | |
|---|---|---|
| 1 | “ODIAN CONSULTING LTD” | 0.5325000000000001 |
| 2 | “Luntrel Investments Limited “ | 0.44750000000000006 |
| 3 | “Milrun International Limited” | 0.405 |
| 4 | “ROMANSTONE INTERNATIONAL LIMITED” | 0.405 |
| 5 | “Varies Foundation” | 0.405 |
| 6 | “MC2 Internacional SA” | 0.34125000000000005 |
| 7 | “Pacific Trust” | 0.2934375 |
| 8 | “The Sri Nithi Trust” | 0.2934375 |
| 9 | “ALLSTAR CONSULTANCY SERVICES LIMITED” | 0.2775 |
| 10 | “AND Holding Ltd” | 0.2775 |
| 11 | “Brockville Development Ltd” | 0.2775 |
| 12 | “Candace Management Limited “ | 0.2775 |
| 13 | “Dominicana Acquisition S.A.” | 0.2775 |
| 14 | “Dorado Asset Management Ltd “ | 0.2775 |
Esta medida de centralidad no resultó muy buena, lo cual se debe a que, por la misma actividad criminal, no existen Officer que sea plenipotenciario sobre TOOOODOS los Entity.
Tampoco es recomendable buscar “comunidades” entre los Officer y los Entities debido a que todos los algoritmos implementados por Neo4j suponen grafos no dirigidos y nodos homogéneos, es decir, de 1 solo tipo.
Node similarity
Vamos a intentar algoritmos de similitud: buscar Officer similares de acuerdo a sus relaciones con sus entities, y así quizá encontrar testaferros o prestanombres:
CALL gds.nodeSimilarity.stream('entitiesAndOfficers')
YIELD node1, node2, similarity
RETURN gds.util.asNode(node1).name AS officer1, gds.util.asNode(node2).name AS officer2, similarity
ORDER BY similarity desc
Vemos que el resultado es:
| officer1 | officer2 | similarity | |
|---|---|---|---|
| 1 | “Uhuru Muigai Kenyatta” | “Mama Ngina Kenyatta” | 1.0 |
| 2 | “Mama Ngina Kenyatta” | “Uhuru Muigai Kenyatta” | 1.0 |
| 3 | “Ngina Kenyatta” | “Kristina Pratt” | 1.0 |
| 4 | “Kristina Pratt” | “Ngina Kenyatta” | 1.0 |
| 5 | “Zakaria Idriss Deby” | “Youssouf Boy Yosko Youssouf” | 1.0 |
| 6 | “Zakaria Idriss Deby” | “David Abtour” | 1.0 |
| 7 | “David Abtour” | “Youssouf Boy Yosko Youssouf” | 1.0 |
| 8 | “David Abtour” | “Zakaria Idriss Deby” | 1.0 |
| 9 | “Youssouf Boy Yosko Youssouf” | “David Abtour” | 1.0 |
| 10 | “Youssouf Boy Yosko Youssouf” | “Zakaria Idriss Deby” | 1.0 |
| 11 | “Sanara Niranthara Rajapaksa Nadesan” | “Thirukumar Ayanaka Nadesan” | 1.0 |
| 12 | “Thirukumar Ayanaka Nadesan” | “Sanara Niranthara Rajapaksa Nadesan” | 1.0 |
| 13 | “Anthony Charles Lynton Blair” | “Cherie Blair” | 1.0 |
| 14 | “Cherie Blair” | “Anthony Charles Lynton Blair” | 1.0 |
| 15 | “Francisco Flores” | “Juan José Daboub” | 1.0 |
| 16 | “Juan José Daboub” | “Francisco Flores” | 1.0 |
| 17 | “Ernesto Pérez Balladares” | “María Enriqueta Pérez Balladares de Iglesias” | 0.6666666666666666 |
| 18 | “María Enriqueta Pérez Balladares de Iglesias” | “Ernesto Pérez Balladares” | 0.6666666666666666 |
| 19 | “Dora María Pérez Balladares Boyd “ | “Isabella Pérez Balladares de Pretelt “ | 0.5 |
| 20 | “Isabella Pérez Balladares de Pretelt “ | “María Enriqueta Pérez Balladares de Iglesias” | 0.5 |
| 21 | “Isabella Pérez Balladares de Pretelt “ | “Dora María Pérez Balladares Boyd “ | 0.5 |
| 22 | “María Enriqueta Pérez Balladares de Iglesias” | “Isabella Pérez Balladares de Pretelt “ | 0.5 |
| 23 | “Luis Enrique Martinelli Linares” | “Ricardo Alberto Martinelli Linares” | 0.5 |
| 24 | “Ricardo Alberto Martinelli Linares” | “Luis Enrique Martinelli Linares” | 0.5 |
| 25 | “César Gaviria” | “Luis Fernando Gaviria Trujillo” | 0.5 |
| 26 | “Luis Fernando Gaviria Trujillo” | “César Gaviria” | 0.5 |
| 27 | “Muhoho Kenyatta” | “Jomo Kamau Muhoho Kenyatta” | 0.4 |
| 28 | “Jomo Kamau Muhoho Kenyatta” | “Muhoho Kenyatta” | 0.4 |
| 29 | “Ernesto Pérez Balladares” | “Isabella Pérez Balladares de Pretelt “ | 0.3333333333333333 |
| 30 | “Dora María Pérez Balladares Boyd “ | “María Enriqueta Pérez Balladares de Iglesias” | 0.3333333333333333 |
| 31 | “Isabella Pérez Balladares de Pretelt “ | “Ernesto Pérez Balladares” | 0.3333333333333333 |
| 32 | “María Enriqueta Pérez Balladares de Iglesias” | “Dora María Pérez Balladares Boyd “ | 0.3333333333333333 |
| 33 | “Ernesto Pérez Balladares” | “Dora María Pérez Balladares Boyd “ | 0.25 |
| 34 | “Dora María Pérez Balladares Boyd “ | “Ernesto Pérez Balladares” | 0.25 |
| 35 | “Sanara Niranthara Rajapaksa Nadesan” | “Thirukumar Nadesan” | 0.25 |
| 36 | “Nirupama Rajapaska” | “Thirukumar Nadesan” | 0.25 |
| 37 | “Thirukumar Nadesan” | “Thirukumar Ayanaka Nadesan” | 0.25 |
| 38 | “Thirukumar Nadesan” | “Nirupama Rajapaska” | 0.25 |
| 39 | “Thirukumar Nadesan” | “Sanara Niranthara Rajapaksa Nadesan” | 0.25 |
| 40 | “Thirukumar Ayanaka Nadesan” | “Thirukumar Nadesan” | 0.25 |
| 41 | “Leyla Aliyeva” | “Arzu Aliyeva” | 0.02702702702702703 |
| 42 | “Arzu Aliyeva” | “Leyla Aliyeva” | 0.02702702702702703 |
Podemos ver que no solamente hay testaferros y prestanombres, sino que además pertenecen a la misma familia. En este caso los primeros 4 registros tienen a prominentes miembros de la familia Kenyatta, descendientes de Jomo Kenyatta, el primer presidente de Kenya post-colonial.
Más ejemplos de law enforcement y proyectos sociales con grafos
- Identificación de células terroristas: https://neo4j.com/blog/graph-technology-fight-terrorist-threats/
- Graphs4Good Project: https://neo4j.com/graphs4good/
Further reading

https://go.neo4j.com/rs/710-RRC-335/images/Neo4j_Graph_Algorithms.pdf