nosql-4-ds
NoSQL Databases 4 Data Science
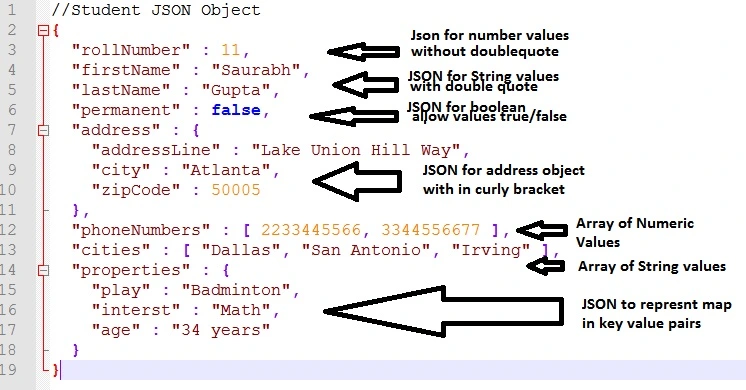
Document Databases - MongoDB
Las Document Databases guardan documentos JSON.
Los documentos JSON, como ya vimos, tienen la sig forma:
Descarga e instalación
- Vamos a descargar la Community Edition de esta liga, dando click en la siguiente ventanita con los settings que aparecen según su sistema operativo:

- Abrimos el instalador y aceptamos los defaults dando click en este botón de esta ventanita. ACEPTEN TODOS LOS DEFAULTS. Es posible que les pida reiniciar:
- La instalación por default va a instalar y abrir MongoDB Compass, que es como el DBeaver de MongoDB. No lo pelen, vamos a instalar un cliente más pro: el RoboMongo. Descárguenlo de aquí. Les va a pedir datos inútiles. Capturen lo que sea para que les permita bajarlo:
- Esto va a bajar un ZIP, y en este ZIP vienen 2 archivos. Hay que instalar solo el Robo 3T, que lo tengo marcado aquí:

- Nos va a salir este choro mareador. Obvio no hay que leerlo y darle I accept:

- Todas estas instalaciones se pueden hacer en paralelo, así que para este momento ya debe estar instalado el MongoDB Community Server. Va a aparecer esta pantalla toda sosa. Den click en Create en la parte de arriba de esa ventana:
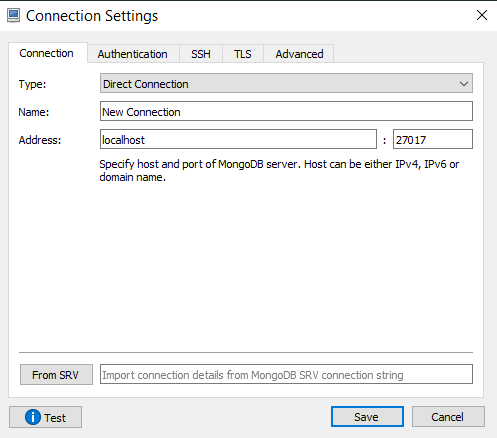
- El string de conexión a nuestra BD local es
mongodb://127.0.0.1:27017/?directConnection=true&serverSelectionTimeoutMS=2000. Vamos a capturarlo en la pantalla siguiente y darle “Save”:
-
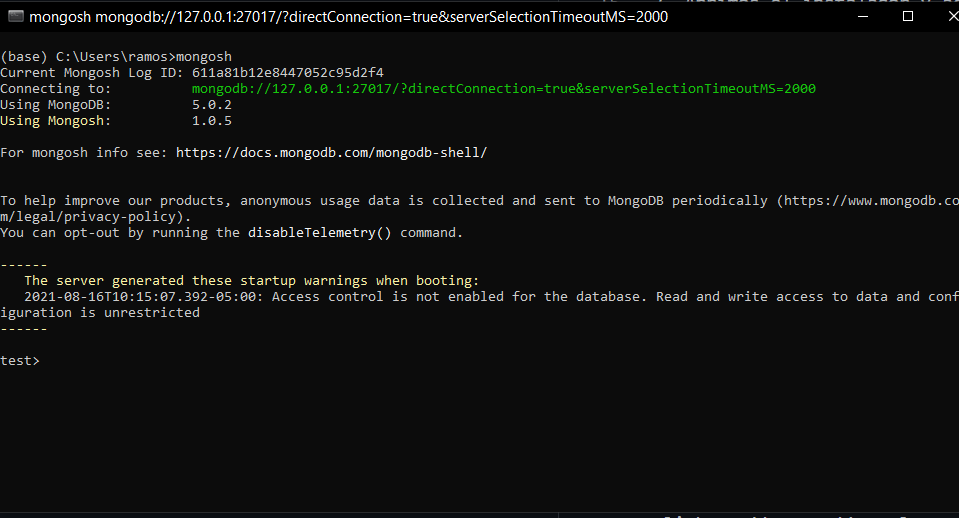
Vamos ahora a instalar el comando
mongosh, que es el shell de MongoDB y que será una 2a forma de interactuar con esa DB. Aquí los pasos para la instalación. Igual acepten todos los defaults. -
Esto nos va a instalar el shell de MongoDB, de modo que al arrancar…
- una terminal de Linux
- una ventana de CMD de Windows
- una terminal de MacOS
DEBEMOS poder tener acceso al comando mongosh. Pruébenlo. Mi salida de Windows debe ser igual a la suya:
Todo esto termina la instalación de mugres que vamos a necesitar para interactuar con MongoDB.
Uso de MongoDB
Creando una DB e insertando documentos
Vamos a usar mongosh para tener una línea de comandos. Entraremos el comando:
use book
De acuerdo a la documentación, este comando “crea una base de datos”, pero esto no es enteramente cierto. Esto solo aparta espacio en el MongoDB para comenzar a agregar documentos (ojo: no son registros). No tenemos una BD formalmente creada hasta no agregar documentos a esa BD.
Para saber qué BD estamos usando:
db
Y para ver todas las DBs que tenemos disponibles:
show dbs
Vamos ahora a agregar un documento:
db.towns.insertOne({
name: "New York",
population: 22200000,
lastCensus: ISODate("2016-07-01"),
famousFor: ["the MOMA", "food", "The Met"],
mayor: {
name: "Bill de Blasio",
party: "D"
}
})
Analicemos línea por línea:
- db es el objeto con el que
mongoshse refiere a la BD que estamos usando, en este casobook. ⚠️IMPORTANTE:warning: - después del elemento db, tenemos el elemento towns, esto es una COLECCIÓN. Recuerden la jerarquía de los JSON:

Esto significa que estamos creando una colección de documentos llamada towns.
Igual, pongan atención a uno de los features más relevantes de las Document Databases: :¡No necesitamos predefinir estructura/esquema para crear colecciones ni documentos! 🤓
Por fin! Libres de la tiranía de tener que definir, pensar, diseñar antes de tirar código!

El insertOne sirve para insertar solo 1 documento en la colección.
El paréntesis que abre ( indica el inicio de los argumentos de la función insertOne.
La llave que abre { indica que viene un documento JSON.
- Inicia el documento con atributos
name(string),population(number),lastCensus(Date),famousFor(array de strings), ymayorde tipo DOCUMENTO, que es otro objeto anidado con sus propios atributos, ⚠️TODO SEPARADO POR COMAS:warning:.
Qué pasa si se nos para una coma❓
Un error como estos:

Fíjense igual que mongosh nos ayuda a identar la función principal, y los documentos anidados.
- Al cerrar llaves y paréntesis, debemos tener esta salida:

Qué pasa si volvemos a ejecutar la misma inserción❓
Las Document Databases no tienen “llaves” como las BDs relacionales, entonces al ejecutar una inserción 2 veces, para MongoDB son objetos enteramente diferentes, y de hecho cada inserción se forma un ID autoasignado diferente (similar a las secuencias de las BDs relacionales). Adicionalmente, MongoDB crea un atributo llamado _id EN AUTOMÁGICO, sin preguntarnos, que es donde se guarda esta llave autogenerada. Este atributo se encuentra en TODOS los documentos de 1er nivel (es decir, no está en los documentos anidados).
Estos IDs autogenerados son de 12 bytes y tienen la siguiente estructura:
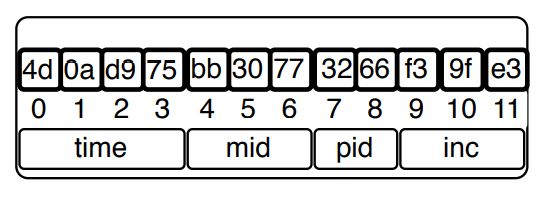
time: timestamp del sistema operativomachine id: ID de la máquinaprocess id: ID del proceso (un concepto de Unix)increment: contador autoincrementado de 3 bytes
Este tipo de IDs autogenerados es que podemos tener varias instancias de MongoDB corriendo en la misma máquina y no tendremos riesgos de colisiones. YAY!
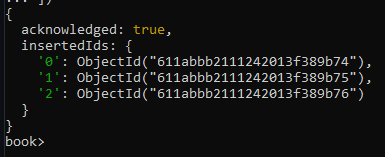
Inertando múltiples documentos
Intentemos ahora:
db.towns.insertMany([
{name: "New York",
population: 22200000,
lastCensus: ISODate("2016-07-01"),
famousFor: ["the MOMA", "food", "The Met"],
mayor: {
name: "Bill de Blasio",
party: "D"
}
},
{name: "London",
population: 15000000,
lastCensus: ISODate("2018-01-01"),
famousFor: ["The British Museum", "Fish & Chips", "The Tate Modern"],
mayor: {
name: "Sadiq Khan",
party: "L"
}
},
{name: "Mexicalpan de las Tunas",
population: 20000000,
lastCensus: ISODate("2019-01-01"),
famousFor: ["Museo Nacional de Antropología", "Tacos de Canasta", "Tlacoyos"],
mayor: {
name: "Claudia Sheinbaum",
party: "MORENA"
}
}
])
Debemos tener esta salida:
SQL es a BDs relacionales como JavaScript es a MongoDB
El lenguaje base de MongoDB es JavaScript. JavaScript tiene mala fama entre la comunidad de ingeniería de software, pero es ampliamente gustado por la comunidad de desarrollo web. Principalmente por su inconsistencia…
…por su abundancia de frameworks inútiles…
…aunque es el primero que nos ofrece productividad expedita.
Usaremos JavaScript para todo con MongoDB, hasta pedor ayuda:
db.help()
db.towns.help()
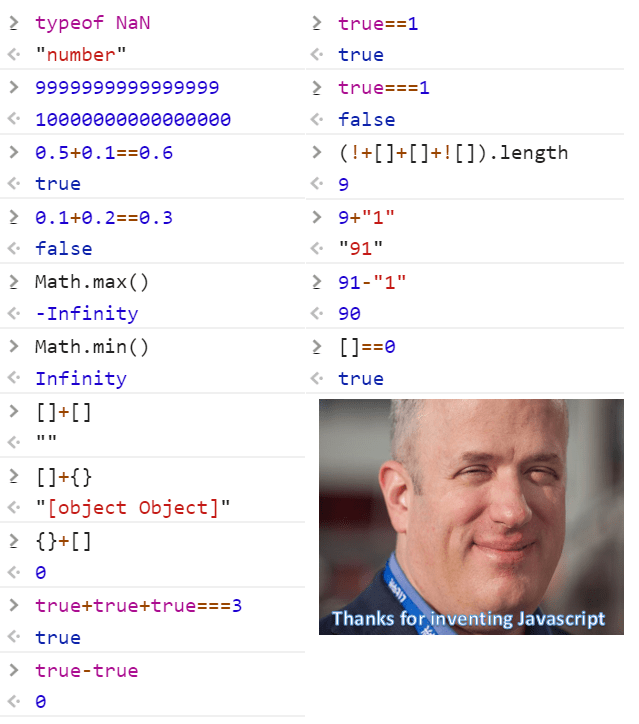
Igual podemos identificar el tipo de un objeto, justo como en JavaScript:
typeof db
typeof db.towns
typeof db.towns.insertOne
Examinemos el código fuente de la función insertOne:
db.towns.insertOne //sin paréntesis
> [Function: insertOne] AsyncFunction {
apiVersions: [ 1, Infinity ],
serverVersions: [ '3.2.0', '999.999.999' ],
returnsPromise: true,
topologies: [ 0, 2, 3, 1 ],
returnType: { type: 'unknown', attributes: {} },
deprecated: false,
platforms: [ 0, 1, 2 ],
isDirectShellCommand: false,
shellCommandCompleter: undefined,
help: [Function (anonymous)] Help
}
Esto sería como ver qué hay dentro del comando INSERT en una BD relacional, cosa que no podemos hacer!
Vamos a crear nuestra propia función para insertar ciudades en la colección db.towns:
function insertCity(name, population, lastCensus, famousFor, mayorInfo) {
db.towns.insertOne({
name: name,
population: population,
lastCensus: ISODate(lastCensus),
famousFor: famousFor,
mayor : mayorInfo
});
}
Esto es como un create function insertcity (string, numeric, date, string, string) AS 'insert into table city values ($1,$2,$3,$4,$5)' para PostgreSQL.
Podemos llamar esta función ahora sin el db.towns.insertOne. No es mucho ahorro, pero con user-defined functions podemos hacer cosas más elaboradas:
insertCity("Punxsutawney", 6200, '2016-01-31', ["Punxsutawney Phil"], { name : "Richard Alexander" })
insertCity("Portland", 582000, '2016-09-20', ["beer", "food", "Portlandia"], { name : "Ted Wheeler", party : "D" })
Leyendo datos: SELECT en SQL, find() en MongoDB
Para ensayar las funciones de consulta, debemos importar algunas BDs de prueba.
- Vamos a clonar este repo en nuestro directorio preferido. Opcionalmente podemos bajar el archivo ZIP de ese URL
git clone https://github.com/neelabalan/mongodb-sample-dataset
-
Vamos a necesitar el comando
mongoimport, que no se instala por default. Lo descargaremos de aquí. -
En Windows muy probablemente el comando se instaló en
C:\Program Files\MongoDB\Tools\100\bin, mientras que el Linux y en Mac ya está instalado. -
Vamos a utilizar el comando import de esa localidad para insertar uno de los JSONs del repo que descargamos:
mongoimport --db trainingsessions --drop --file C:\Users\ramos\mongodb-sample-dataset\sample_training\tweets.json
- Validamos que haya sido insertada esa colección correctamente:
use trainingsessions
db.getCollectionNames()
db.tweets.find()
Ahora si vamos a leer estos datos. Para leer datos en MongoDB la función base es find():
db.towns.find()trae todos los documentos de la coleccióntowns.db.towns.find({ "_id" : ObjectId("611ce2e73afe7ee944574e51") })va a traer el documento con ID611ce2e73afe7ee944574e51. Recordemos que los ID son autogenerados y el atributo_ides creado automáticamentedb.towns.find( {"_id" : ObjectId("611ce2e73afe7ee944574e51")}, {population : 1} )va a traer el documento con ID611ce2e73afe7ee944574e51pero solo su atributopopulationsimilar a unselect population from towns where id = 611ce2e73afe7ee944574e51db.towns.find( {"_id" : ObjectId("611ce2e73afe7ee944574e51")}, {population : 0} )va a traer el mismo documento, pero ahora con todos sus atributos EXCEPTOpopulationdb.towns.find( {population : 6200})va a traer el documento conpopulationigual a 6200db.towns.find( {name : "London"})va a traer el documento connameigual a “London”
En general, podemos decir que la función find() frecuentemente es llamada con 2 documentos como argumento:
- 1 para filtrado, similar al
WHEREde SQL. Esto se le llama FILTER en bases de datos de documentos. - 1 para selección de atributos, similar al
SELECTde SQL. Esto se le llama PROJECT en bases de datos de documentos.
Vamos a establecer algunas equivalencias entre SQL y MongoDB con la siguiente tabla y la colección tweets que acabamos de importar. Para ejecutar los ejemplos primero debemos entrar use trainingsessions.
| Operación | Sintaxis | E.g. | Equivalencia RDBMS |
|---|---|---|---|
| Igual a X | {"key":[value]} |
db.tweets.find({"source":"web"}) |
where source = ‘web’ |
| AND en el WHERE | {"key1":[value1],"key2":[value2]} |
db.tweets.find({"source":"web","favorited":false}) |
where source = ‘web’ and favorited = false |
| Menor que | {"key":{$lt:[value]}} |
db.tweets.find({"user.friends_count":{$lt:50}}) |
where user.friends_count < 50 (aquí estamos “viajando” del documento principal al documento anidado user y de ahí a su atributo friends_count |
| Menor o igual a | {"key":{$lte:[value]}} |
db.tweets.find({"user.friends_count":{$lte:50}}) |
where user.friends_count <= 50 |
| Mayor que | {"key":{$gt:[value]}} |
db.tweets.find({"user.friends_count":{$gt:50}}) |
where user.friends_count > 50 |
| Mayor o igual a | {"key":{$gte:[value]}} |
db.tweets.find({"user.friends_count":{$gte:50}}) |
where user.friends_count >= 50 |
| Diferente a | {"key":{$ne:[value]}} |
db.tweets.find({"user.friends_count":{$ne:50}}) |
where user.friends_count != 50 |
| Valores presentes en array | {"key":{$in:[value1,value2...valueN]}} |
db.tweets.find({"entities.urls.indices":{$in:[54,74]}}) |
where entities.urls.indices in (54,74) |
| Valores ausentes en array | {"key":{$nin:[value]}} |
db.tweets.find({"entities.urls.indices":{$nin:[54,74]}}) |
where entities.urls.indices not in (54,74) |
Uso de expresiones regulares en find()
Para lograr emular el LIKE de SQL en MongoDB, debemos usar forzosamente expresiones regulares. Por ejemplo:
db.tweets.find({"user.url":/^http(s|):\/\/(www\.|)facebook\.com/})
Esto es similar a la sentencia SQL:
...where user.url like 'http?://facebook.com%'
Esto va a encontrar todos los tuits cuyo URL del perfil de usuario sean ligas a perfiles de FB.
Para encontrar todos los tuits con el hashtag que comience on #polit:
db.tweets.find({"entities.hashtags.text":/^polit/})
En este caso, el caracter ^ indica que el match debe darse desde el principio, porque si no lo ponemos, vamos a hacer match con este tuit que anda por ahí:
{
"_id":{
"$oid":"5c8eccb1caa187d17ca64de8"
},
"text":"Balmoral, booze and the rest of Blair's book digested http://bit.ly/9KwcSP #Blair #AJourney #UKpolitics #Labour #Bush",
"in_reply_to_status_id":null,
"retweet_count":null,
"contributors":null,
"created_at":"Thu Sep 02 18:34:32 +0000 2010",
"geo":null,
"source":"<a href=\"http://www.tweetdeck.com\" rel=\"nofollow\">TweetDeck</a>",
"coordinates":null,
"in_reply_to_screen_name":null,
"truncated":false,
"entities":{
"user_mentions":[
],
"urls":[
{
"indices":[
55,
75
],
"url":"http://bit.ly/9KwcSP",
"expanded_url":null
}
],
"hashtags":[
{
"text":"Blair",
"indices":[
77,
83
]
},
{
"text":"AJourney",
"indices":[
84,
93
]
},
{
"text":"UKpolitics",
"indices":[
94,
105
]
},
{
"text":"Labour",
"indices":[
106,
113
]
},
{
"text":"Bush",
"indices":[
114,
119
]
}
]
},
"retweeted":false,
"place":null,
"user":{
"friends_count":556,
"profile_sidebar_fill_color":"DDEEF6",
"location":"",
"verified":false,
"follow_request_sent":null,
"favourites_count":0,
"profile_sidebar_border_color":"C0DEED",
"profile_image_url":"http://a2.twimg.com/profile_images/1026348478/US-UK-blend_normal.png",
"geo_enabled":false,
"created_at":"Sat Jun 26 14:58:34 +0000 2010",
"description":"Promoting and discussing the special relatonship between the United States and the United Kingdom.",
"time_zone":null,
"url":null,
"screen_name":"USUKrelations",
"notifications":null,
"profile_background_color":"C0DEED",
"listed_count":4,
"lang":"en",
"profile_background_image_url":"http://a3.twimg.com/profile_background_images/116769793/specialrelations.jpg",
"statuses_count":647,
"following":null,
"profile_text_color":"333333",
"protected":false,
"show_all_inline_media":false,
"profile_background_tile":true,
"name":"Special Relationship",
"contributors_enabled":false,
"profile_link_color":"0084B4",
"followers_count":264,
"id":159870717,
"profile_use_background_image":true,
"utc_offset":null
},
"favorited":false,
"in_reply_to_user_id":null,
"id":{
"$numberLong":"22820800600"
}
}
En esta materia no veremos a fondo expresiones regulares, pero aquí 2 ligas útiles:
- https://regexone.com/ es un crash course rápido para aprender las bases de las expresiones regulares
- https://regexr.com/ es una plataformita para probar sus regexp contra ejemplos suyos o de terceros
⚠️IMPORTANTE:⚠️ Las expresiones regulares que deben ir en estos queries son Perl-compatible Regular Expressions (PCRE)
Queries a arrays
A diferencia de las RDBMS, las Document Databases aceptan en sus atributos arrays de valores.
Recuerden que las reglas de diseño de las relacionales nos obligan a que un atributo tenga solo 1 valor, mientras que en las de documentos un atributo puede ser un string, un número, o un arreglo de cualquiera de ambos.
Este query va a regresar el documento que tenga ÚNICA Y EXACTA Y ORDENADAMENTE los elementos 54 y 74.
db.tweets.find({"entities.urls.indices":[54,74]})
Osea, si hay un elemento que tiene el orden 74 y 54, no no lo va a encontrar.
Para buscarlos a todos, sin importar orden, usamos el operador $all:
db.tweets.find({"entities.urls.indices":{$all:[54,74]}})
Para buscar todos los documentos que AL MENOS tengan uno de los elementos:
db.tweets.find({"entities.urls.indices":54})
O usar el operador $in que vimos arriba.
Para buscar un rango en un array numérico, en este caso, entre 50 y 90, inclusive:
db.tweets.find({"entities.urls.indices":{$lte:50, $gte:90}})
Y para buscar documentos cuyo N-avo elemento sea igual a X:
db.tweets.find({"entities.urls.indices.1":59})
Recordemos que los arrays en MongoDB están indexados desde 0 y no desde 1.
Para buscar un documento por el tamaño de uno de sus atributos de tipo array:
db.tweets.find({"entities.hashtags":{$size:7}})
Y para buscar documentos cuyos atributos tipo array tengan más de 7 elementos:
db.tweets.find({"entities.hashtags.7":{$exists:true}})
Podemos combinar operadores $exists, $gte y $lte para buscar documentos que tengan un array entre N y M elementos. El siguiente query regresa los tuits que tengan EXACTAMENTE un hashtag, aprovechando la dot notation (.) para viajar de entities->hashtags->[elemento del array con índice 0] y verificar su existencia con {$exists:true}, y hacer elk mismo viaje al [elemento del array con índice 1] y asegurarnos que no existe con {$exists:false}.
db.tweets.find({"entities.hashtags.1":{$exists:false},"entities.hashtags.0":{$exists:true}},{"entities":1})
El racional de esta forma de find() es que si buscamos arrays con num de elementos mayores a 7, entonces tendremos arrays cuyo elemento en la posición 7 (que realmente es la posición 8 porque comenzamos desde 0) debe tener un elemento presente.
Queries a documentos anidados y arrays de documentos
Para los siguientes ejemplos vamos a insertar estos documentos con la función insertMany():
[
{
"item":"journal",
"instock":[
{
"warehouse":"A",
"qty":5
},
{
"warehouse":"C",
"qty":15
}
]
},
{
"item":"notebook",
"instock":[
{
"warehouse":"C",
"qty":5
}
]
},
{
"item":"paper",
"instock":[
{
"warehouse":"A",
"qty":60
},
{
"warehouse":"B",
"qty":15
}
]
},
{
"item":"planner",
"instock":[
{
"warehouse":"A",
"qty":40
},
{
"warehouse":"B",
"qty":5
}
]
},
{
"item":"postcard",
"instock":[
{
"warehouse":"B",
"qty":15
},
{
"warehouse":"C",
"qty":35
}
]
}
]
- Creen una nueva BD llamada
warehouse - Creen una colección llamada
inventory - Inserten estos documentos de arriba
El siguiente query va a regresar todos los artículos que estén en en warehouse A y de los que tengamos 5 en inventario:
db.inventory.find( { "instock": { warehouse: "A", qty: 5 } } )
El valor de retorno es:
[
{
_id: ObjectId("612339842cd2fe46682acd32"),
item: 'journal',
instock: [ { warehouse: 'A', qty: 5 }, { warehouse: 'C', qty: 15 } ]
}
]
El query no nos está regresando 2 documentos, sino el documento en el array instock que hace match con las condiciones que le dimos.
👀OJO:👀 esta sintaxis es parecida a la búsqueda de documentos de 1er nivel (find("key1":value1,"key2":value2), pero como estamos buscando documentos ANIDADOS O EN ARRAY, entonces debemos de especificar el nombre del array instock antes de los params de búsqueda.
Una gran diferencia es en el orden de los atributos que estemos buscando en el array de documentos. Por ejemplo, si ejecutamos esto:
db.inventory.fnd( { "instock": { qty: 5, warehouse: "A" } } )
Va a regresar NADA, porque ningún documento dentro del array tiene primero el atributo qty.
El siguiente query va a regresar todos los documentos de instock que tengan un qty menor o igual a 20, junto con los documentos que acompañen a ese que hace match:
db.inventory.find( { "instock.qty": { $lte: 20 } } )
Este query también es similar a los que vimos para consultar documentos de 1er nivel, con la diferencia de que instock es un array de documentos y no un atributo o un array de elementos individuales.
Si deseamos limitar la búsqueda a un índice del array, como para evitar tener un documento que no cumpla con las condiciones, podemos especificarlo así:
db.inventory.find( { 'instock.0.qty': { $lte: 20 } } )
Este query nos regresará del arreglo instock los PRIMEROS documentos (índice 0) cuyo atributo qty sea igual o menor a 20.
El operador $elemMatch
Hay estructuras de documentos de varios niveles y con arreglos anidados donde al lanzar queries a estos arreglos puede regresarnos documentos que no necesariamente cumplen el criterio.
- Vamos a crear otra BD llamada “store”
- Con una colección llamada “articles”
- Insertamos este array de documentos con
insertMany
db.articles.insert([
{
"_id" : 1,
"description" : "DESCRIPTION ARTICLE AB",
"article_code" : "AB",
"purchase" : [
{
"company" : 1,
"cost" : NumberDecimal("80.010000")
},
{
"company" : 2,
"cost" : NumberDecimal("85.820000")
},
{
"company" : 3,
"cost" : NumberDecimal("79.910000")
}
],
"stock" : [
{
"country" : "01",
"warehouse" : {
"code" : "02",
"units" : 10
}
},
{
"country" : "02",
"warehouse" : {
"code" : "02",
"units" : 8
}
}
]
},
{
"_id" : 2,
"description" : "DESCRIPTION ARTICLE AC",
"article_code" : "AC",
"purchase" : [
{
"company" : 1,
"cost" : NumberDecimal("90.010000")
},
{
"company" : 2,
"cost" : NumberDecimal("95.820000")
},
{
"company" : 3,
"cost" : NumberDecimal("89.910000")
}
],
"stock" : [
{
"country" : "01",
"warehouse" : {
"code" : "01",
"units" : 20
}
},
{
"country" : "02",
"warehouse" : {
"code" : "02",
"units" : 28
}
}
]
}
]);
Qué función find() necesitamos para obtener los “artículos” con stock en el warehouse 02 en el country 01?
db.articles.find({"stock.country":"01","stock.warehouse.code":"02"})
Ese query nos va a regresar los 2 documentos que insertamos:
{
"_id" : 1,
"description" : "DESCRIPTION ARTICLE AB",
"article_code" : "AB",
"purchase" : [
{
"company" : 1,
"cost" : NumberDecimal("80.010000")
},
{
"company" : 2,
"cost" : NumberDecimal("85.820000")
},
{
"company" : 3,
"cost" : NumberDecimal("79.910000")
}
],
"stock" : [
{
"country" : "01",
"warehouse" : {
"code" : "02",
"units" : 10
}
},
{
"country" : "02",
"warehouse" : {
"code" : "02",
"units" : 8
}
}
]
}
{
"_id" : 2,
"description" : "DESCRIPTION ARTICLE AC",
"article_code" : "AC",
"purchase" : [
{
"company" : 1,
"cost" : NumberDecimal("90.010000")
},
{
"company" : 2,
"cost" : NumberDecimal("95.820000")
},
{
"company" : 3,
"cost" : NumberDecimal("89.910000")
}
],
"stock" : [
{
"country" : "01",
"warehouse" : {
"code" : "01",
"units" : 20
}
},
{
"country" : "02",
"warehouse" : {
"code" : "02",
"units" : 28
}
}
]
}
Como podemos ver, el array stock del documento de 1er nivel con _id 2 cumple con las condiciones POR SEPARADO, por lo tanto este query nos puede regresar resultados espurios _si es que estamos buscando solamente el documento cuyo array stock tenga un elemento que cumpla CON AMBOS CRITERIOS.
Para tener el comportamiento esperado, debemos usar el operador $elemMatch:
db.articles.find({ stock : { $elemMatch : { country : "01", "warehouse.code" : "02" } } })
Esto nos debe dar el documento correcto:
{
"_id" : 1,
"description" : "DESCRIPTION ARTICLE AB",
"article_code" : "AB",
"purchase" : [
{
"company" : 1,
"cost" : NumberDecimal("80.010000")
},
{
"company" : 2,
"cost" : NumberDecimal("85.820000")
},
{
"company" : 3,
"cost" : NumberDecimal("79.910000")
}
],
"stock" : [
{
"country" : "01",
"warehouse" : {
"code" : "02",
"units" : 10
}
},
{
"country" : "02",
"warehouse" : {
"code" : "02",
"units" : 8
}
}
]
}
El operador $elemMatch sirve para encontrar elementos individuales que cumplan con múltiples criterios TODOS JUNTOS (a manera de and), al contrario del funcionamiento normal sobre arrays, donde nos regresa los arreglos que cumplan con AL MENOS uno de los criterios POR SEPARADO.
El operador $slice
El operador $slice, por su parte, “rebana” un arreglo de un documento para regresarnos solamente N elementos:
db.articles.find({},{"purchase":{$slice:1}})
Este query nos regresará todos los documentos, pero su array purchase solo tendrá el 1er elemento. $slice acepta números positivos para “rebanar” el array de izq a derecha, y números negativos para “rebanarlo” de derecha a izq:}
db.articles.find({},{"purchase":{$slice:-2}})
Del mismo modo, podemos usar el operador $slice para obtener un elemento en específico del array usando la forma find({},{atributo:{$slice:[indice_inicio, numero_de_elementos]}}. El siguiente comando traerá solamente el 2o elemento de los arrays purchase.
db.articles.find({},{purchase:{$slice:[1,1]}})
Aquí nos posicionamos en el índice 1 (el 2o elemento), y a partir de ahí, traemos 1 elemento.
Ejercicios
Usaremos la BD restaurants.json para estos ejercicios.
Primero debemos descargar el archivo restaurants.json de este repo.
Luego lo debemos cargar con mongoimport:
mongoimport --db=reviews --collection=restaurants --file=restaurants.json
Debemos tener esta salida:

La estructura de esta colección de documentos es la siguiente (aunque recuerden que no nos debemos fiar, porque MongoDB no tiene estructura predefinida).
{
"address": {
"building": "1007",
"coord": [ -73.856077, 40.848447 ],
"street": "Morris Park Ave",
"zipcode": "10462"
},
"borough": "Bronx",
"cuisine": "Bakery",
"grades": [
{ "date": { "$date": 1393804800000 }, "grade": "A", "score": 2 },
{ "date": { "$date": 1378857600000 }, "grade": "A", "score": 6 },
{ "date": { "$date": 1358985600000 }, "grade": "A", "score": 10 },
{ "date": { "$date": 1322006400000 }, "grade": "A", "score": 9 },
{ "date": { "$date": 1299715200000 }, "grade": "B", "score": 14 }
],
"name": "Morris Park Bake Shop",
"restaurant_id": "30075445"
}
Vamos a responder las siguientes preguntas:
- Escribe una función find() para mostrar todos los documentos de la colección de restaurantes.
db.restaurants.find()
- Escribe una función find() para mostrar los campos restaurant_id, nombre, municipio y cocina para todos los documentos en el restaurante de la colección.
db.restaurants.find({},{restaurant_id:1,name:1,borough:1,cuisine:1})
- Escribe una función find() para mostrar los campos restaurant_id, nombre, municipio y cocina, pero excluya el campo _id para todos los documentos de la colección restaurant.
db.restaurants.find({},{restaurant_id:1,name:1,borough:1,cuisine:1,_id:0})
- Escribe una función find() para mostrar los campos restaurant_id, nombre, municipio y código postal, pero excluya el campo _id para todos los documentos de la colección restaurant.
db.restaurants.find({},{restaurant_id:1,name:1,borough:1,"address.zipcode":1,_id:0})
- Escribe una función find() para mostrar todos los restaurantes que se encuentran en el distrito del Bronx.
db.restaurants.find({borough:"Bronx"})
- Escribe una función find() para mostrar los primeros 5 restaurantes que se encuentran en el condado del Bronx.
db.restaurants.find({borough:"Bronx"}).limit(5)
- Escribe una función find() para mostrar los siguientes 5 restaurantes después de omitir los primeros 5 que se encuentran en el condado del Bronx.
db.restaurants.find({borough:"Bronx"}).skip(5).limit(5)
- Escribe una función find() para encontrar los restaurantes que obtuvieron una puntuación de más de 90.
db.restaurants.find({"grades.score":{$gt:90}},{"grades.score":1})
Como podemos ver aquí, se cumple la regla de MongoDB donde en un query a un array, si todas las condiciones por separado son cumplidas por algunos elementos del array, se regresa todo el array.
- Escribe una función find() para encontrar los restaurantes que obtuvieron una puntuación, más de 80 pero menos de 100.
El siguiente query cumple con la regla que mencionamos arriba.
db.restaurants.find({"grades.score":{$gt:80,$lt:100}},{"grades.score":1})
Y por ello tenemos elementos del array de score como 131, el cual es mayor a 80, y 11, que es menor a 100.
Para buscar los elementos que cumplan exactamente con ambos criterios debemos usar el operador $elemMatch:
db.restaurants.find({"grades":{$elemMatch:{"score":{$gt:80,$lt:100}}}},{"grades.score":1})
Y de ese modo obtenemos arreglos que tengan al menos 1 elemento que cumpla con ambos criterios.
- Escribe una función find() para encontrar los restaurantes que se ubican en un valor de latitud menor que -95.754168.
Suponiendo que el atributo tipo array coord tiene la latitud en el índice 0:
db.restaurants.find({"address.coord.0":{$lte:-95.754168}},{"address.coord":1})
- Escribe una función find() para encontrar los restaurantes que no preparan ningún tipo de cocina de ‘estadounidense’ y su puntuación de calificación es superior a 70 y latitud inferior a -65.754168.
Tenemos 2 opciones. Sin expresiones regulares, usando el oeprador not equals ($ne) y atendiendo que por alguna razón el tipo de cocina "American " tiene un espacio al final:
db.restaurants.find({"cuisine":{$ne:"American "},"grades.score":{$gt:70},"address.coord.0":{$lt:-65.754168}},{"cuisine":1,"grades":1,"address.coord":1})
O con expresiones regulares y ayudándonos del operador booleano $not. Usamos el ^ para indicar “inicio de línea”, y así evitar sacar del query a los restaurantes de cocina “Latin American/Caribbean”:
db.restaurants.find({"cuisine":{$not:/^American/},"grades.score":{$gt:70},"address.coord.0":{$lt:-65.754168}},{"cuisine":1,"grades":1,"address.coord":1})
- Escribe una función find() para encontrar los restaurantes que no preparan ninguna cocina del continente americano y lograron una puntuación superior a 70 y se ubicaron en la longitud inferior a -65.754168.
db.restaurants.find(
{
"cuisine" : {$ne : "American "},
"grades.score" :{$gt: 70},
"address.coord" : {$lt : -65.754168}
}
);
- Escribe una función find() para encontrar los restaurantes que no preparan ninguna cocina del continente americano y obtuvieron una calificación de ‘A’ que no pertenece al distrito de Brooklyn. El documento debe mostrarse según la cocina en orden descendente.
db.restaurants.find( {
"cuisine" : {$ne : "American "},
"grades.grade" :"A",
"borough": {$ne : "Brooklyn"}
}
).sort({"cuisine":-1});
- Escribe una función find() para encontrar el ID del restaurante, el nombre, el municipio y la cocina de aquellos restaurantes que contienen ‘Wil’ como las primeras tres letras de su nombre.
db.restaurants.find({name: /^Wil/}, {"restaurant_id":1, "name":1, "borough":1, "cuisine":1});
- Escribe una función find() para encontrar el ID del restaurante, el nombre, el municipio y la cocina de aquellos restaurantes que contienen “ces” como las últimas tres letras de su nombre.
db.restaurants.find({name: /ces$/},{"restaurant_id" : 1,"name":1,"borough":1,"cuisine" :1});
- Escribe una función find() para encontrar el ID del restaurante, el nombre, el municipio y la cocina de aquellos restaurantes que contienen ‘Reg’ como tres letras en algún lugar de su nombre.
db.restaurants.find( { "name": /Reg/ }, { "restaurant_id": 1, "name": 1, "borough": 1, "cuisine": 1 });
O alternativamente:
db.restaurants.find( { "name": /.*Reg.*/ }, { "restaurant_id": 1, "name": 1, "borough": 1, "cuisine": 1 });
- Escribe una función find() para encontrar los restaurantes que pertenecen al municipio del Bronx y que prepararon platos estadounidenses o chinos.
db.restaurants.find(
{
"borough": "Bronx" ,
$or : [
{ "cuisine" : "American " },
{ "cuisine" : "Chinese" }
]
}
);
- Escribe una función find() para encontrar la identificación del restaurante, el nombre, el municipio y la cocina de los restaurantes que pertenecen al municipio de Staten Island o Queens o Bronxor Brooklyn.
db.restaurants.find(
{"borough" :
{$in :["Staten Island","Queens","Bronx","Brooklyn"]}
},
{
"restaurant_id" : 1,
"name":1,
"borough":1,
"cuisine" :1
}
);
- Escribe una función find() para encontrar el ID del restaurante, el nombre, el municipio y la cocina de aquellos restaurantes que no pertenecen al municipio de Staten Island o Queens o Bronxor Brooklyn.
db.restaurants.find(
{"borough" :
{$nin :["Staten Island","Queens","Bronx","Brooklyn"]}
},
{
"restaurant_id" : 1,
"name":1,
"borough":1,
"cuisine" :1
}
);
- Escribe una función find() para encontrar el ID del restaurante, el nombre, el municipio y la cocina de aquellos restaurantes que obtuvieron una puntuación que no sea superior a 10.
db.restaurants.find(
{"grades.score" :
{ $not: {$gt : 10}}
},
{
"restaurant_id" : 1,
"name":1,
"borough":1,
"cuisine" :1
}
);
Alternativamente…
db.restaurants.find(
{"grades.score" :
{$lte : 10}
},
{
"restaurant_id" : 1,
"name":1,
"borough":1,
"cuisine" :1
}
);
- Escribe una función find() para encontrar el ID del restaurante, el nombre, el municipio y la cocina de aquellos restaurantes que prepararon platos excepto ‘Americano’ y ‘Chinese’ o el nombre del restaurante comienza con la letra ‘Wil’.
db.restaurants.find(
{$or: [
{name: /^Wil/},
{"$and": [
{"cuisine" : {$ne :"American "}},
{"cuisine" : {$ne :"Chinese"}} ]
}]
}
,{
"restaurant_id" : 1,
"name":1,
"borough":1,
"cuisine" :1
}
);
- Escribe una función find() para encontrar el ID del restaurante, el nombre y las calificaciones de los restaurantes que obtuvieron una calificación de “A” y obtuvieron una puntuación de 11 en un ISODate “2014-08-11T00: 00: 00Z” entre muchas de las fechas de la encuesta. .
db.restaurants.find(
{
"grades.date": ISODate("2014-08-11T00:00:00Z"),
"grades.grade":"A" ,
"grades.score" : 11
},
{
"restaurant_id" : 1,
"name":1,
"grades":1
}
);
👀OJO👀: Aquí la palabra clave es “entre muchas de las fechas de la encuesta”, porque implica el comportamiento esperado de los queries sobre los arrays, en donde todos sus elementos deben de ayudar a cumplir todas las condiciones. En este caso, entre todos los grades deben ayudar a cumplir el criterio de 1) fecha del 11 de Agosto de 2014, 2) grade = A, y 3) score = 11.
- Escribe una función find() para encontrar el ID del restaurante, el nombre y las calificaciones de aquellos restaurantes donde el segundo elemento de la matriz de calificaciones contiene una calificación de “A” y una puntuación de 9 en un ISODate “2014-08-11T00: 00: 00Z”.
db.restaurants.find(
{
"grades.1.date":ISODate("2014-08-11T00:00:00Z"),
"grades.1.grade":"A",
"grades.1.score" : 9
},
{
restaurant_id" : 1,
"name":1,
"grades":1
}
);
Si intentamos buscar estos criterios y que los satisfaga 1 y solo 1 elemento del array con $elemMatch:
db.restaurants.find( {"grades.1": {$elemMatch:{"date": ISODate("2014-08-11T00:00:00Z"), "grade": "A", "score": 9 }}}, { "restaurant_id": 1, "name": 1, "grades": 1 });
No vamos a encontrar nada.
Esto es porque $elemMatch espera como entrada un array, y al apuntar la búsqueda a grades.1 estamos pasando solo 1 elemento.
Si en lugar de grades.1 pasamos todo el arreglo de grades a $elemMatch:
db.restaurants.find( {"grades": {$elemMatch:{"date": ISODate("2014-08-11T00:00:00Z"), "grade": "A", "score": 9 }}}, { "restaurant_id": 1, "name": 1, "grades": 1 });
Nos regresa los 2 restaurantes cuyos grades tienen elementos que cumplen con los 3 criterios.
- Escribe una función find() para encontrar el ID del restaurante, el nombre, la dirección y la ubicación geográfica para aquellos restaurantes donde el segundo elemento de la matriz de coordenadas contiene un valor que sea más de 42 y hasta 52.
db.restaurants.find(
{
"address.coord.1": {$gt : 42, $lte : 52}
},
{
"restaurant_id" : 1,
"name":1,
"address":1,
"coord":1
}
);
- Escribe una función find() para organizar el nombre de los restaurantes en orden ascendente junto con todas las columnas.
db.restaurants.find().sort({"name":1});
- Escribe una función find() para organizar el nombre de los restaurantes en orden descendente junto con todas las columnas.
db.restaurants.find().sort({"name":-1});
- Escribe una función find() para organizar el nombre de la cocina en orden ascendente y para ese mismo distrito de cocina debe estar en orden descendente.
db.restaurants.find().sort({"cuisine":1,"borough" : -1,});
- Escribe una función find() para saber si todas las direcciones contienen la calle o no.
db.restaurants.find({"address.street" : { $exists : true } } );
Otras formas de checar existencia (o nulidad) son:
- usando la condición
{"address.street" : {$type : 10}}, que checa que el tipo seanull(ver ejercicio 29) - usando
{"address.street" : null}
- Escribe una función find() que seleccionará todos los documentos de la colección de restaurantes donde el valor del campo coord es Double.
db.restaurants.find({"address.coord" : {$type : 1} } );
El operador $type nos permite explorar el tipo de dato que tiene un atributo. Recordemos que javascript es weakly-typed y las variables no tienen tipo hasta que tienen un dato. A continuación los valores $type comunes:
| Type | Number | Alias | Notes |
|---|---|---|---|
| Double | 1 | “double” | |
| String | 2 | “string” | |
| Object | 3 | “object” | |
| Array | 4 | “array” | |
| Binary data | 5 | “binData” | |
| Undefined | 6 | “undefined” | Deprecated. |
| ObjectId | 7 | “objectId” | |
| Boolean | 8 | “bool” | |
| Date | 9 | “date” | |
| Null | 10 | “null” | |
| Regular Expression | 11 | “regex” | |
| 32-bit integer | 16 | “int” | |
| Timestamp | 17 | “timestamp” | |
| 64-bit integer | 18 | “long” | |
| Decimal128 | 19 | “decimal” | New in version 3.4. |
- Escribe una función find() que seleccionará el ID del restaurante, el nombre y las calificaciones para esos restaurantes que devuelve 0 como resto después de dividir la puntuación por 7.
db.restaurants.find({"grades.score" : {$mod : [7,0]} }, {"restaurant_id" : 1,"name":1,"grades":1});
- Escribe una función find() para encontrar el nombre del restaurante, el municipio, la longitud y la actitud y la cocina de aquellos restaurantes que contienen “mon” como tres letras en algún lugar de su nombre.
db.restaurants.find(
{
name : {
$regex : "mon.*", $options: "i"
}
},
{
"name":1,
"borough":1,
"address.coord":1,
"cuisine" :1
}
);
El operador $options modifica como se comportará la expresión regular. En este caso, $options:"i" realiza una búsqueda case insensitive, por lo que va a hacer match con “Mon”, “mon”, “MON”, “MoN”, “moN”, etc.
- Escribe una función find() para encontrar el nombre del restaurante, el distrito, la longitud y la latitud y la cocina de aquellos restaurantes que contienen ‘Mad’ como las primeras tres letras de su nombre.
db.restaurants.find(
{
name : {
$regex : /^Mad/i
}
},
{
"name":1,
"borough":1,
"address.coord":1,
"cuisine" :1
}
);
Al igual que el caso anterior, pero la ubicación de las opciones modificadoras de la expresión regular es dentro de la expresión misma mediante la sintaxis /patrón_1/opción, similar al comando sed de Unix.
Agregaciones
Las agregaciones son queries que colapsan registros individuales en un solo resultado al mismo tiempo que aplican algún operador sobre ellos como conteo, sumar, promedios, etc.
Estas operaciones destruyen información, es decir, el promedio, suma o conteo del grupo colapsado pierde información de cada miembro individual.
Como analistas de datos pocas veces haremos agregaciones directo en las bases de datos fuente, y probablemente primero las movamos a nuestro data lake y ahí hacerlas. Pero si no tuvieramos uno, esta es la forma de hacerlas:
Para esta parte de la sesión vamos a crear la BD 3tdb y laa colecciones universities y courses
use 3tdb;
db.universities.insertMany([
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
},
{
country : 'Spain',
city : 'Salamanca',
name : 'UPSA',
location : {
type : 'Point',
coordinates : [ -5.6691191,17, 40.9631732 ]
},
students : [
{ year : 2014, number : 4788 },
{ year : 2015, number : 4821 },
{ year : 2016, number : 6550 },
{ year : 2017, number : 6125 }
]
}
]);
db.courses.insertMany([
{
university : 'USAL',
name : 'Computer Science',
level : 'Excellent'
},
{
university : 'USAL',
name : 'Electronics',
level : 'Intermediate'
},
{
university : 'USAL',
name : 'Communication',
level : 'Excellent'
}
]);
Las agregaciones en MongoDB se hacen a través de PIPELINES, esto tiene la siguiente forma:
funcion_f(w).funcion_g(x).funcion_h(y).funcion_i(z)
Estos pipelines son idénticos a hacer esto:
funcion_f(funcion_g(funcion_h(funcion_i(w,x,y,z))))
Con la diferencia que esto es mucho menos legible.
Un pipeline primero debe ser definido:
var pipeline = [
{"$match": {
"level": "Excellent",
}},
{"$sort": {
"name": -1,
}},
{"$limit": 1},
{"$unset": [
"_id",
"name",
"level",
]},
];
Si se fijan, estamos definiendo un arreglo de condiciones y operadores.
Para ejecutar este pipeline:
db.courses.aggregate(pipeline);
Y para que MongoDB nos expliquen el execution plan:
db.courses.explain("executionStats").aggregate(pipeline);
El resultado esperado es:
[ { university: 'USAL' } ]
NOTAS:
- Podemos acelerar el query con un índice. Qué campos incluirían en dicho índice?
- Estamos usando
$unseten lugar de$project, que es lo mismo que usar{"atributo":[1|0]}. - Oiga, pero esto podemos hacerlo con
findsolito!
Si, de este modo:
db.courses.find(
{"level": "Excellent"},
{"_id": 0, "name": 0, "level": 0},
).sort(
{"name": -1}
).limit(1);
Pero tenemos menos legibilidad y no podemos encadenar operaciones de agregación, como las que siguen.
En general, un pipeline de agregación en MongoDB tiene la siguiente forma:
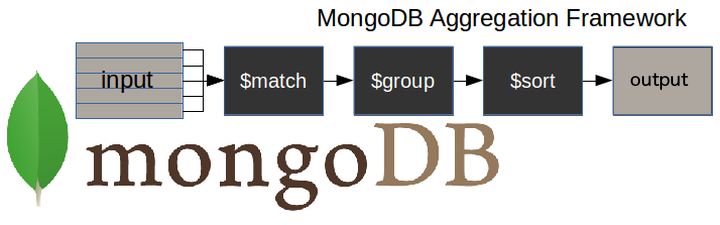
Es una generalización de una secuencia de funciones:
$match: filtrado de todos los documentos que nos interesan para el query (como elWHEREen SQL). Se puede conjuntar con$project.$group: agrega los renglones seleccionados previo a aplicar algun operador$sort: ordena los resultados de acuerdo a un criterio
El input de la agregación puede ser 1 o más documentos en array.
No hay límites en cuanto al num de elementos de cada tipo para el pipeline (les llamamos stages), es decir, podemos combinar cualquier número de operadores. SIN EMBARGO el límite por pipeline en cuanto a su memory footprint es de 100MB.
Stage $match
El primer stage en los pipelines de agregación es similar al find() para filtrar documentos en los que estamos interesados:
db.universities.aggregate([
{ $match : { country : 'Spain', city : 'Salamanca' } }
])
Y al igual que el find(), podemos hacer $project:
db.universities.aggregate([
{ $match:{country: 'Spain', city: 'Salamanca'} },
{ $project:{_id : 0, country : 1, city : 1, name : 1} }
])
Stage $group
El group by de MongoDB y el corazón de operaciones como count, sum, avg, etc.
db.universities.aggregate([
{ $match:{country: 'Spain', city: 'Salamanca'} },
{ $project:{_id : 0, country : 1, city : 1, name : 1} },
{ $group:{_id: "$name", conteo:{$sum:1}} },
{ $project:{_id : 0, "uni" : "$_id"} }
])
👀OJO!👀 En el $group hay algunos elementos de sintaxis mandatorios:
- el atributo de agrupación se debe llamar
_id.- Podemos renombrarlo agregando otro stage de
$projectasí:db.universities.aggregate([ { $match:{country: 'Spain', city: 'Salamanca'} }, { $project:{_id : 0, country : 1, city : 1, name : 1} }, { $group:{_id: "$name", conteo:{$sum:1}} }, { $project:{_id : 0, "uni" : "$_id"} } ])
- Podemos renombrarlo agregando otro stage de
- el atributo por el cual vamos a agregar debe ir con la notación
$como si se tratara de una variable (porque lo es) y entrecomillado. - el atributo en el cual guardaremos el resultado de la función de agregación puede llamarse como nosotros deseemos
{$sum:1}es similar alCOUNT(*)de SQL en el sentido de que va sumando 1 por cada documento que encuentra de acuerdo al stage de$match
Caso especial: agregación total (sin grupos)
En caso de que deseemos hacer una agregación de todos los documentos, sin armar grupos:
db.universities.aggregate([
{ $match:{country: 'Spain', city: 'Salamanca'} },
{ $project:{_id : 0, country : 1, city : 1, name : 1} },
{ $group: { _id: null, conteo: { $count: {} } } }
{ $project: { _id: 0, conteo:1 } }
])
Resultado:
[ { conteo: 2 } ]
Stage $out
Toma la ejecución de toda la salida del pipeline y lo guarda en otra colección.
db.universities.aggregate([
{ $match:{country: 'Spain', city: 'Salamanca'} },
{ $project:{_id : 0, country : 1, city : 1, name : 1} },
{ $group:{_id: "$name", conteo:{$sum:1}} },
{ $project:{_id : 0, "uni" : "$_id", conteo:1} },
{ $out:"miranomas" }
])
Stage $unwind
Si nuestros documentos tienen arrays, el stage $group no nos permite llegar a ellos para agregarlos.
El stage $unwind nos permite un hack para darle la vuelta a esta limitante.
Lo que hace es explotar el array de un documento, tomar cada uno de los N elementos, y clavárselos a N copias del atributo que lo contiene.
En efecto, lo “desenrolla” 🤣
Por ejemplo:
db.universities.aggregate([
{ $match : { name : 'USAL' } }
])
Esto obviamente nos regresa 1 documento:
{
country : 'Spain',
city : 'Salamanca',
name : 'USAL',
location : {
type : 'Point',
coordinates : [ -5.6722512,17, 40.9607792 ]
},
students : [
{ year : 2014, number : 24774 },
{ year : 2015, number : 23166 },
{ year : 2016, number : 21913 },
{ year : 2017, number : 21715 }
]
}
Pero si corremos la siguiente agregación:
db.universities.aggregate([
{ $match : { name : 'USAL' } },
{ $unwind : '$students' }
])
Entonces tenemos el siguiente resultado:
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2014,
"number" : 24774
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2015,
"number" : 23166
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2016,
"number" : 21913
}
}
{
"_id" : ObjectId("5b7d9d9efbc9884f689cdba9"),
"country" : "Spain",
"city" : "Salamanca",
"name" : "USAL",
"location" : {
"type" : "Point",
"coordinates" : [
-5.6722512,
17,
40.9607792
]
},
"students" : {
"year" : 2017,
"number" : 21715
}
}
👀OJO!👀 Fíjense en el _id que ES EL MISMO en todos los casos, esto es, es el mismo objeto university pero con el array students descompuesto e insertado en copias de cada elemento.
Casos especiales
$unwindde un array vacío no regresará nada$unwindde un atributo simple regresará el mismo enclosing document$unwindde un array de un diccionario que tiene un 2o o 3er array, solo va a “desenrollar” el diccionario que solicitamos en ese operador, por lo que los otros arrays estarán repetidos
Para qué sirve esto?
Para hacer cosas como contar los registros de alumnos de 2017:
db.universities.aggregate([
{ $unwind : '$students' },
{ $project : { _id : 0, 'students.year' : 1, 'students.number' : 1 } },
{ $match: {'students.year':2017}},
{ $group:{_id: "$students.year", conteo:{$count:{}}} },
])
O acumular los alumnos de cada año:
db.universities.aggregate([
{ $unwind: '$students' },
{ $project: { _id: 0, "name": 1, 'students.year': 1, 'students.number': 1 } },
{ $group: { _id: "$students.year", totalAlumnos: { $sum: "$students.number" } } },
{$project:{_id:0,"ano":"$_id",totalAlumnos:1}}
])
O el promedio de alumnos de 2014 a 2017
db.universities.aggregate([
{ $unwind: '$students' },
{ $project: { _id: 0, "name": 1, 'students.year': 1, 'students.number': 1 } },
{ $group: { _id: "$name", promedioAlumnos: { $avg: "$students.number" } } },
{$project:{_id:0,"uni":"$_id",promedioAlumnos:1}}
])
O cualquiera de estas funciones:
| Función | Descrip |
|---|---|
| $addToSet | Después de agrupar, agrega elementos individuales a un array |
| $avg | Promedio |
| $count | Conteo (igual a {$sum:1} |
| $first | Regresa el 1er documento o diccionario de cada grupo. ⚠️No confundir con el operador $first aplicable a arrays. Este operador no se ocupa del orden, eso se garantiza desde el stage $sort del pipeline |
| $last | Regresa el último documento o diccionario de cada grupo. Mismas reglas y observaciones que $first |
| $max | Regresa el máximo de cada grupo |
| $mergeObjects | Después de armar los grupos, combinar los objetos/diccionarios/documentos que correspondan al grupo en uno solo |
| $min | Regresa el mínimo de cada grupo |
| $stdDevPop | Regresa la desviación estándar de la población (entre n) de cada grupo |
| $stdDevSamp | Regresa la desviación estándar de la muestra (entre n-1) de cada grupo |
| $sum | Suma acumulativa de cada grupo |
Ejemplo $addToSet
Vamos a crear la sig colección en la BD que sea:
db.sales.insertMany([
{ "_id" : 1, "item" : "abc", "price" : 10, "quantity" : 2, "date" : ISODate("2014-01-01T08:00:00Z") },
{ "_id" : 2, "item" : "jkl", "price" : 20, "quantity" : 1, "date" : ISODate("2014-02-03T09:00:00Z") },
{ "_id" : 3, "item" : "xyz", "price" : 5, "quantity" : 5, "date" : ISODate("2014-02-03T09:05:00Z") },
{ "_id" : 4, "item" : "abc", "price" : 10, "quantity" : 10, "date" : ISODate("2014-02-15T08:00:00Z") },
{ "_id" : 5, "item" : "xyz", "price" : 5, "quantity" : 10, "date" : ISODate("2014-02-15T09:12:00Z") }
]);
Vemos que solo hay 2 fechas. Si queremos agrupar por esa fecha y aglutinar los item en un solo array, podemos hacer:
db.sales.aggregate([
{$group:
{_id: { day: { $dayOfYear: "$date"}, year: { $year: "$date" } }, itemsSold: { $addToSet: "$item" } }
}
]);
👀OJO!👀 Estamos utilizando 2 operadores para objetos ISODate:
$dayOfYear: extrae de un objetoISODateun dato numérico entre 1 y 365 (o 366 si es año bisiesto) representando el día del año.$year: extrae de un objetoISODateel año en numérico.
A continuación los operadores más comunes sobre ISODate:
| Función | Descripción y Ejemplo |
|---|---|
| $dateAdd | { $dateAdd: {startDate: ISODate("2020-10-31T12:10:05Z"), unit: "month", amount: 1} } - Agrega amount al campo unit de la fecha startDate |
| $dateDiff | { $dateDiff: { startDate: ISODate("2014-01-01T08:00:00Z"), endDate: ISODate("2014-02-03T09:00:00Z"), unit: "day"} } - Regresa la diferencia en unit entre startDate y endDate |
| $dateFromString | { $dateFromString: {dateString: "15-06-2018", format: "%d-%m-%Y"} } - Parsea el string dateString representando una fecha en formato format para convertirlo en un objeto ISODate que contenga esa misma fecha. |
| $dateSubtract | { $dateSubtract: {startDate: ISODate("2020-10-31T12:10:05Z"), unit: "month", amount: 1} } - Susbtrae amount al campo unit de la fecha startDate |
| $dateToParts | $dateToParts: { date: ISODate("2017-01-01T01:29:09.123Z") } - Descompone el date en sus partes. Retorna "date" : {"year" : 2017, "month" : 1, "day" : 1, "hour" : 1, "minute" : 29, "second" : 9, "millisecond" : 123} |
| $dateToString | { $dateToString: { format: "%Y-%m-%d %H:%M:%S", date: ISODate("2014-01-01T08:15:39.736Z") } } - Convierte un ISODate en un string con una fecha formateada por format. Retorna "2014-01-01 03:15:39". Ver opciones de formato. |
| $dayOfMonth | Los siguientes operadores tienen la sintaxis { $[operador]: [objeto ISODate] }. Regresa un numérico entre 1 y 31 del objeto ISODate. |
| $dayOfWeek | Regresa un numérico entre 1 (Domingo) y 7 (Sábado) del objeto ISODate. |
| $dayOfYear | Regresa un numérico entre 1 y 366 (bisiesto) del objeto ISODate. |
| $hour | Regresa un numérico entre 0 y 23 del objeto ISODate. |
| $isoDayOfWeek | Regresa un numérico entre 1 (Lunes) y 7 (Domingo) del objeto ISODate. No confundir con $dayOfWeek |
| $isoWeek | Regresa un numérico entre 1 y 53 del objeto ISODate. |
| $millisecond | Regresa un numérico entre 0 y 999 del objeto ISODate. |
| $minute | Reegresa un numérico entre 0 y 59 del objeto ISODate. |
| $month | Regresa un numérico entre 1 (Enero) y 12 (Diciembre) del objeto ISODate. |
| $second | Regresa un numérico entre 0 y 60 (cuando es leap second) del objeto ISODate. |
| $year | Regresa el valor del año del objeto ISODate |
Posterior a armar los grupos con esas 2 únicas fechas, cada item será agregado a un array:
{ "_id" : { "day" : 46, "year" : 2014 }, "itemsSold" : [ "xyz", "abc" ] }
{ "_id" : { "day" : 34, "year" : 2014 }, "itemsSold" : [ "xyz", "jkl" ] }
{ "_id" : { "day" : 1, "year" : 2014 }, "itemsSold" : [ "abc" ] }
Ejemplo $mergeObjects
Crearemos la sig colección en cualquier BD:
db.sales.insert( [
{ _id: 1, year: 2017, item: "A", quantity: { "2017Q1": 500, "2017Q2": 500 } },
{ _id: 2, year: 2016, item: "A", quantity: { "2016Q1": 400, "2016Q2": 300, "2016Q3": 0, "2016Q4": 0 } } ,
{ _id: 3, year: 2017, item: "B", quantity: { "2017Q1": 300 } },
{ _id: 4, year: 2016, item: "B", quantity: { "2016Q3": 100, "2016Q4": 250 } }
])
Vamos a agrupar por item y vamos a crear un diccionario con todos los quantity en un atributo llamado mergedSales:
db.sales.aggregate( [
{ $group: { _id: "$item", mergedSales: { $mergeObjects: "$quantity" } } }
])
El resultado debe ser:
{ "_id" : "B", "mergedSales" : { "2017Q1" : 300, "2016Q3" : 100, "2016Q4" : 250 } }
{ "_id" : "A", "mergedSales" : { "2017Q1" : 500, "2017Q2" : 500, "2016Q1" : 400, "2016Q2" : 300, "2016Q3" : 0, "2016Q4" : 0 } }
Stages $sort y $limit
El sort y el limit puede usarse como stage de un pipeline de agregación, o puede usarse standalone como lo hemos hecho antes para ordenar resulsets individuales.
Stage $addFields
Crea campos nuevos basados en las agregaciones, como una suma concentrada final, o un promedio concentrado final.
⚠️No confundir con el $group, el $addFields NO AGREGA NI AGRUPA.⚠️
Regresemos a nuestra BD de reviews de restaurantes con use reviews
La estructura de cada review es:
{
_id: ObjectId("612d222983a7f8a60c193d14"),
address: {
building: '351',
coord: [ -73.98513559999999, 40.7676919 ],
street: 'West 57 Street',
zipcode: '10019'
},
borough: 'Manhattan',
cuisine: 'Irish',
grades: [
{ date: ISODate("2014-09-06T00:00:00.000Z"), grade: 'A', score: 2 },
{
date: ISODate("2013-07-22T00:00:00.000Z"),
grade: 'A',
score: 11
},
{
date: ISODate("2012-07-31T00:00:00.000Z"),
grade: 'A',
score: 12
},
{
date: ISODate("2011-12-29T00:00:00.000Z"),
grade: 'A',
score: 12
}
],
name: 'Dj Reynolds Pub And Restaurant',
restaurant_id: '30191841'
}
Cómo podemos agregar un atributo a cada restaurante para tener su score total agregado de todos sus reviews y su promedio?
db.restaurants.aggregate([
{$unwind:"$grades"},
{$project:{"grades.score":1, "name":1}},
{$group:{_id:"$name", "gradeArray":{$push:"$grades.score"}}},
{$project:{"name":"$_id",_id:0,"gradeArray":1}},
{$addFields:{"totalScore":{$sum:"$gradeArray"},"avgScore":{$avg:"$gradeArray"}}}
])
Desmenucemos este query para entenderlo:
- “desenrollo” el array
gradesy le clavo cada elemento a una copia del enclosing object. - quito toda la paja y me quedo con los scores y el nombre del restaurante
- agrupo por nombre de restaurante - esto en SQL es una mala práctica, PERO en MongoDB y en general en bases de datos de documentos, se vale. Esto nos sirve para poder ejecutar el operador
$push, que clava un array a un objeto. En esta línea lo que estamos haciendo es efectivamente CONVERTIR el diccionario que tiene los scores en un arreglo normalito. - Ya con el arreglo, renombramos el
_iddel grupo - Y sumamos horizontalmente los scores del array, así como su promedio.
Stage $sortByCount
Es un operador que funge como si tuviéramos:
db.collection.aggregate([
{ $group: { _id: <expression>, count: { $sum: 1 } } },
{ $sort: { count: -1 } }
])
Insertemos esta base de datos de obras de arte:
db.artwork.insertMany([
{ "_id" : 1, "title" : "The Pillars of Society", "artist" : "Grosz", "year" : 1926, "tags" : [ "painting", "satire", "Expressionism", "caricature" ] },
{ "_id" : 2, "title" : "Melancholy III", "artist" : "Munch", "year" : 1902, "tags" : [ "woodcut", "Expressionism" ] },
{ "_id" : 3, "title" : "Dancer", "artist" : "Miro", "year" : 1925, "tags" : [ "oil", "Surrealism", "painting" ] },
{ "_id" : 4, "title" : "The Great Wave off Kanagawa", "artist" : "Hokusai", "tags" : [ "woodblock", "ukiyo-e" ] },
{ "_id" : 5, "title" : "The Persistence of Memory", "artist" : "Dali", "year" : 1931, "tags" : [ "Surrealism", "painting", "oil" ] },
{ "_id" : 6, "title" : "Composition VII", "artist" : "Kandinsky", "year" : 1913, "tags" : [ "oil", "painting", "abstract" ] },
{ "_id" : 7, "title" : "The Scream", "artist" : "Munch", "year" : 1893, "tags" : [ "Expressionism", "painting", "oil" ] },
{ "_id" : 8, "title" : "Blue Flower", "artist" : "O'Keefe", "year" : 1918, "tags" : [ "abstract", "painting" ] },
])
Si ejecutamos la siguiente agregación:
db.exhibits.aggregate( [ { $unwind: "$tags" }, { $sortByCount: "$tags" } ] )
Tendremos la salida:
{ "_id" : "painting", "count" : 6 }
{ "_id" : "oil", "count" : 4 }
{ "_id" : "Expressionism", "count" : 3 }
{ "_id" : "Surrealism", "count" : 2 }
{ "_id" : "abstract", "count" : 2 }
{ "_id" : "woodblock", "count" : 1 }
{ "_id" : "woodcut", "count" : 1 }
{ "_id" : "ukiyo-e", "count" : 1 }
{ "_id" : "satire", "count" : 1 }
{ "_id" : "caricature", "count" : 1 }
Esto es, cuenta los elementos comunes y los ordena por el num de ocurrencias.
Queries analíticos avanzados
- Cuál es el promedio de
scoreportypede evaluación y porclass_iden la BDsample_trainingen la coleccióngrades?
Para esto debemos descargar esta BD de calificaciones e insertarla con mongoimport:
mongoimport --db=sample_training --collection=grades
Primero debemos enterarnos de qué va la BD. Vamos a sacar los primeros 3 registros para ver de qué tratan:
use sample_training
db.grades.find().limit(3)
[
{
_id: ObjectId("56d5f7eb604eb380b0d8d8ce"),
student_id: 0,
scores: [
{ type: 'exam', score: 78.40446309504266 },
{ type: 'quiz', score: 73.36224783231339 },
{ type: 'homework', score: 46.980982486720535 },
{ type: 'homework', score: 76.67556138656222 }
],
class_id: 339
},
{
_id: ObjectId("56d5f7eb604eb380b0d8d8d6"),
student_id: 0,
scores: [
{ type: 'exam', score: 25.926204502143857 },
{ type: 'quiz', score: 37.23668404170315 },
{ type: 'homework', score: 19.609679551976487 },
{ type: 'homework', score: 98.7923690220697 }
],
class_id: 108
},
{
_id: ObjectId("56d5f7eb604eb380b0d8d8da"),
student_id: 1,
scores: [
{ type: 'exam', score: 95.4702770345805 },
{ type: 'quiz', score: 59.14125426136129 },
{ type: 'homework', score: 34.32836889016887 },
{ type: 'homework', score: 84.07534235774499 }
],
class_id: 237
}
]
Parece que son calificaciones de un alumno, de una clase, para diferentes mecanismos de evaluación: examen, quiz, y tareas.
Qué tipo de relación hay entre student_id y class_id? Cuál es el punto de vista de esta estructura? “Una clase tiene N alumnos?”, o “un alumno tiene N clases?”.
Primero, veamos cuantos registros tenemos:
db.grades.find().count()
1000000
Si la perspectiva está anclada en class_id, entonces deberíamos tener 1000000 clases, o 1000000 estudiantes si la perspectiva está en student_id.
db.grades.distinct("class_id")
[
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,
12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23,
24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,
36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47,
48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59,
60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71,
72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83,
84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95,
96, 97, 98, 99,
... 401 more items
]
De acuerdo a esto, el universo de clases es mucho menor, por lo que probablemente esta colección esté armada desde la perspectiva del estudiante.
db.grades.distinct("student_id")
[
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,
12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23,
24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,
36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47,
48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59,
60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71,
72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83,
84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95,
96, 97, 98, 99,
... 9900 more items
]
Ahora vamos a tratar de armar el query para dar respuesta a la pregunta inicial:
db.grades.aggregate([
{$unwind:"$scores"},{$project:{"student_id":0}},
{$group:{_id:{"clase":"$class_id","eval":"$scores.type"}, "promedio":{$avg:"$scores.score"}}},
{$sort:{"_id.clase":1,"_id.eval":1}}])
])
Nuestro resultado es:
[
{ _id: { clase: 0, eval: 'exam' }, promedio: 46.224870203904395 },
{ _id: { clase: 0, eval: 'homework' }, promedio: 49.6592370300883 },
{ _id: { clase: 0, eval: 'quiz' }, promedio: 49.38124259163944 },
{ _id: { clase: 1, eval: 'exam' }, promedio: 50.78357850094616 },
{ _id: { clase: 1, eval: 'homework' }, promedio: 49.18339520790678 },
{ _id: { clase: 1, eval: 'quiz' }, promedio: 51.68365158823541 },
{ _id: { clase: 2, eval: 'exam' }, promedio: 51.212269415215715 },
{ _id: { clase: 2, eval: 'homework' }, promedio: 48.635517471345494 },
{ _id: { clase: 2, eval: 'quiz' }, promedio: 49.22183768413837 },
{ _id: { clase: 3, eval: 'exam' }, promedio: 49.24088016851434 },
{ _id: { clase: 3, eval: 'homework' }, promedio: 49.32958980280401 },
{ _id: { clase: 3, eval: 'quiz' }, promedio: 49.70705542324686 },
{ _id: { clase: 4, eval: 'exam' }, promedio: 48.45214274611575 },
{ _id: { clase: 4, eval: 'homework' }, promedio: 51.336198599567986 },
{ _id: { clase: 4, eval: 'quiz' }, promedio: 52.186677392814204 },
{ _id: { clase: 5, eval: 'exam' }, promedio: 51.91626171544547 },
{ _id: { clase: 5, eval: 'homework' }, promedio: 49.71133512774075 },
{ _id: { clase: 5, eval: 'quiz' }, promedio: 48.17571458478485 },
{ _id: { clase: 6, eval: 'exam' }, promedio: 54.20236080762028 },
{ _id: { clase: 6, eval: 'homework' }, promedio: 49.441178234623834 },
...,
...,
...,
]
Stage $lookup
Este stage nos permite hacer un join entre la colección sobre la que estamos operando y una colección de lookup.
Se recomienda que ambas colecciones estén en la misma BD.
Al igual que las operaciones join en SQL, necesitamos que ambas colecciones tengan al menos 1 atributo idéntico cada uno los cuales podamos asociar con una condición de igualdad. Recordemos que en MongoDB los ObjectID no siguen (ni tienen por qué seguir) las mejores prácticas de identificadores que en SQL.
Para este ejercicio vamos a importar 2 colecciones a la BD lookup:
use lookup
db.orders.insert([
{ "_id" : 1, "item" : "almonds", "price" : 12, "quantity" : 2 },
{ "_id" : 2, "item" : "pecans", "price" : 20, "quantity" : 1 },
{ "_id" : 3 }
])
db.inventory.insert([
{ "_id" : 1, "sku" : "almonds", "description": "product 1", "instock" : 120 },
{ "_id" : 2, "sku" : "bread", "description": "product 2", "instock" : 80 },
{ "_id" : 3, "sku" : "cashews", "description": "product 3", "instock" : 60 },
{ "_id" : 4, "sku" : "pecans", "description": "product 4", "instock" : 70 },
{ "_id" : 5, "sku": null, "description": "Incomplete" },
{ "_id" : 6 }
])
Y luego corremos el operador $lookup como parte de un pipeline de la función .aggregate()
db.orders.aggregate([
{
$lookup:
{
from: "inventory",
localField: "item",
foreignField: "sku",
as: "inventory_docs"
}
}
])
El resultado es:
{
"_id" : 1,
"item" : "almonds",
"price" : 12,
"quantity" : 2,
"inventory_docs" : [
{ "_id" : 1, "sku" : "almonds", "description" : "product 1", "instock" : 120 }
]
}
{
"_id" : 2,
"item" : "pecans",
"price" : 20,
"quantity" : 1,
"inventory_docs" : [
{ "_id" : 4, "sku" : "pecans", "description" : "product 4", "instock" : 70 }
]
}
{
"_id" : 3,
"inventory_docs" : [
{ "_id" : 5, "sku" : null, "description" : "Incomplete" },
{ "_id" : 6 }
]
}
Posterior a esto podríamos continuar el pipeline, por ejemplo, para contar los inventory_docs por diccionario:
db.orders.aggregate([
{
$lookup:
{
from: "inventory",
localField: "item",
foreignField: "sku",
as: "inventory_docs"
}
},
{$unwind:"$inventory_docs"},
{$group: {_id:"$_id", numDocs:{$count:{}}}}
])
Ejercicio Integrador
Usando la colección de tweets en la BD trainingsessions vamos a responder las siguientes preguntas, ayudándonos de las siguientes colecciones adicionales.
db.primarydialects.insertMany([
{"lang":"af", "locale":"af-ZA"},
{"lang":"ar", "locale":"ar"},
{"lang":"bg", "locale":"bg-BG"},
{"lang":"ca", "locale":"ca-AD"},
{"lang":"cs", "locale":"cs-CZ"},
{"lang":"cy", "locale":"cy-GB"},
{"lang":"da", "locale":"da-DK"},
{"lang":"de", "locale":"de-DE"},
{"lang":"el", "locale":"el-GR"},
{"lang":"en", "locale":"en-US"},
{"lang":"es", "locale":"es-ES"},
{"lang":"et", "locale":"et-EE"},
{"lang":"eu", "locale":"eu"},
{"lang":"fa", "locale":"fa-IR"},
{"lang":"fi", "locale":"fi-FI"},
{"lang":"fr", "locale":"fr-FR"},
{"lang":"he", "locale":"he-IL"},
{"lang":"hi", "locale":"hi-IN"},
{"lang":"hr", "locale":"hr-HR"},
{"lang":"hu", "locale":"hu-HU"},
{"lang":"id", "locale":"id-ID"},
{"lang":"is", "locale":"is-IS"},
{"lang":"it", "locale":"it-IT"},
{"lang":"ja", "locale":"ja-JP"},
{"lang":"km", "locale":"km-KH"},
{"lang":"ko", "locale":"ko-KR"},
{"lang":"la", "locale":"la"},
{"lang":"lt", "locale":"lt-LT"},
{"lang":"lv", "locale":"lv-LV"},
{"lang":"mn", "locale":"mn-MN"},
{"lang":"nb", "locale":"nb-NO"},
{"lang":"nl", "locale":"nl-NL"},
{"lang":"nn", "locale":"nn-NO"},
{"lang":"pl", "locale":"pl-PL"},
{"lang":"pt", "locale":"pt-PT"},
{"lang":"ro", "locale":"ro-RO"},
{"lang":"ru", "locale":"ru-RU"},
{"lang":"sk", "locale":"sk-SK"},
{"lang":"sl", "locale":"sl-SI"},
{"lang":"sr", "locale":"sr-RS"},
{"lang":"sv", "locale":"sv-SE"},
{"lang":"th", "locale":"th-TH"},
{"lang":"tr", "locale":"tr-TR"},
{"lang":"uk", "locale":"uk-UA"},
{"lang":"vi", "locale":"vi-VN"},
{"lang":"zh", "locale":"zh-CN"}
])
db.languagenames.insertMany([{"locale":"af-ZA", "languages":[
"Afrikaans",
"Afrikaans"
]},
{"locale":"ar", "languages":[
"العربية",
"Arabic"
]},
{"locale":"bg-BG", "languages":[
"Български",
"Bulgarian"
]},
{"locale":"ca-AD", "languages":[
"Català",
"Catalan"
]},
{"locale":"cs-CZ", "languages":[
"Čeština",
"Czech"
]},
{"locale":"cy-GB", "languages":[
"Cymraeg",
"Welsh"
]},
{"locale":"da-DK", "languages":[
"Dansk",
"Danish"
]},
{"locale":"de-AT", "languages":[
"Deutsch (Österreich)",
"German (Austria)"
]},
{"locale":"de-CH", "languages":[
"Deutsch (Schweiz)",
"German (Switzerland)"
]},
{"locale":"de-DE", "languages":[
"Deutsch (Deutschland)",
"German (Germany)"
]},
{"locale":"el-GR", "languages":[
"Ελληνικά",
"Greek"
]},
{"locale":"en-GB", "languages":[
"English (UK)",
"English (UK)"
]},
{"locale":"en-US", "languages":[
"English (US)",
"English (US)"
]},
{"locale":"es-CL", "languages":[
"Español (Chile)",
"Spanish (Chile)"
]},
{"locale":"es-ES", "languages":[
"Español (España)",
"Spanish (Spain)"
]},
{"locale":"es-MX", "languages":[
"Español (México)",
"Spanish (Mexico)"
]},
{"locale":"et-EE", "languages":[
"Eesti keel",
"Estonian"
]},
{"locale":"eu", "languages":[
"Euskara",
"Basque"
]},
{"locale":"fa-IR", "languages":[
"فارسی",
"Persian"
]},
{"locale":"fi-FI", "languages":[
"Suomi",
"Finnish"
]},
{"locale":"fr-CA", "languages":[
"Français (Canada)",
"French (Canada)"
]},
{"locale":"fr-FR", "languages":[
"Français (France)",
"French (France)"
]},
{"locale":"he-IL", "languages":[
"עברית",
"Hebrew"
]},
{"locale":"hi-IN", "languages":[
"हिंदी",
"Hindi"
]},
{"locale":"hr-HR", "languages":[
"Hrvatski",
"Croatian"
]},
{"locale":"hu-HU", "languages":[
"Magyar",
"Hungarian"
]},
{"locale":"id-ID", "languages":[
"Bahasa Indonesia",
"Indonesian"
]},
{"locale":"is-IS", "languages":[
"Íslenska",
"Icelandic"
]},
{"locale":"it-IT", "languages":[
"Italiano",
"Italian"
]},
{"locale":"ja-JP", "languages":[
"日本語",
"Japanese"
]},
{"locale":"km-KH", "languages":[
"ភាសាខ្មែរ",
"Khmer"
]},
{"locale":"ko-KR", "languages":[
"한국어",
"Korean"
]},
{"locale":"la", "languages":[
"Latina",
"Latin"
]},
{"locale":"lt-LT", "languages":[
"Lietuvių kalba",
"Lithuanian"
]},
{"locale":"lv-LV", "languages":[
"Latviešu",
"Latvian"
]},
{"locale":"mn-MN", "languages":[
"Монгол",
"Mongolian"
]},
{"locale":"nb-NO", "languages":[
"Norsk bokmål",
"Norwegian (Bokmål)"
]},
{"locale":"nl-NL", "languages":[
"Nederlands",
"Dutch"
]},
{"locale":"nn-NO", "languages":[
"Norsk nynorsk",
"Norwegian (Nynorsk)"
]},
{"locale":"pl-PL", "languages":[
"Polski",
"Polish"
]},
{"locale":"pt-BR", "languages":[
"Português (Brasil)",
"Portuguese (Brazil)"
]},
{"locale":"pt-PT", "languages":[
"Português (Portugal)",
"Portuguese (Portugal)"
]},
{"locale":"ro-RO", "languages":[
"Română",
"Romanian"
]},
{"locale":"ru-RU", "languages":[
"Русский",
"Russian"
]},
{"locale":"sk-SK", "languages":[
"Slovenčina",
"Slovak"
]},
{"locale":"sl-SI", "languages":[
"Slovenščina",
"Slovenian"
]},
{"locale":"sr-RS", "languages":[
"Српски / Srpski",
"Serbian"
]},
{"locale":"sv-SE", "languages":[
"Svenska",
"Swedish"
]},
{"locale":"th-TH", "languages":[
"ไทย",
"Thai"
]},
{"locale":"tr-TR", "languages":[
"Türkçe",
"Turkish"
]},
{"locale":"uk-UA", "languages":[
"Українська",
"Ukrainian"
]},
{"locale":"vi-VN", "languages":[
"Tiếng Việt",
"Vietnamese"
]},
{"locale":"zh-CN", "languages":[
"中文 (中国大陆)",
"Chinese (PRC)"
]},
{"locale":"zh-TW", "languages":[
"中文 (台灣)",
"Chinese (Taiwan)"
]}]);
- Qué idiomas base son los que más tuitean con hashtags? Cuál con URLs? Y con @?
# Con Hashtags
db.tweets.aggregate([
{$lookup: {from:"primarydialects","localField":"user.lang","foreignField":"lang","as":"language"}},
{$lookup: {from:"languagenames","localField":"language.locale","foreignField":"locale","as":"fulllocale"}},
{$match:{"entities.hashtags":{$not:{$size:0}}}},
{$group: {_id:"$fulllocale.languages", "conteo": {$count:{}}}}
])
# Con URLs
db.tweets.aggregate([
{$lookup: {from:"primarydialects","localField":"user.lang","foreignField":"lang","as":"language"}},
{$lookup: {from:"languagenames","localField":"language.locale","foreignField":"locale","as":"fulllocale"}},
{$match:{"entities.urls":{$not:{$size:0}}}},
{$group: {_id:"$fulllocale.languages", "conteo": {$count:{}}}}
])
# Con User Mentions
db.tweets.aggregate([
{$lookup: {from:"primarydialects","localField":"user.lang","foreignField":"lang","as":"language"}},
{$lookup: {from:"languagenames","localField":"language.locale","foreignField":"locale","as":"fulllocale"}},
{$match:{"entities.user_mentions":{$not:{$size:0}}}},
{$group: {_id:"$fulllocale.languages", "conteo": {$count:{}}}}
])
⚠️ OFERTA!! Puntos extra por jalar los 3 resultados en 1 solo query! ⚠️
➡️ Podemos hacer este query más eficiente? ➡️
db.tweets.aggregate([
{$lookup: {from:"primarydialects","localField":"user.lang","foreignField":"lang","as":"language"}},
{$lookup: {from:"languagenames","localField":"language.locale","foreignField":"locale","as":"fulllocale"}},
{$match:{"entities.user_mentions":{$not:{$size:0}}}},
{$group: {_id:"$fulllocale.languages", "conteo": {$count:{}}}}
]).explain()
# 4413 ms
⚔️ VERSUS ⚔️
db.tweets.aggregate([
{$match:{"entities.user_mentions":{$not:{$size:0}}}},
{$group: {_id:"$user.lang", "conteo": {$count:{}}}},
{$lookup: {from:"primarydialects","localField":"_id","foreignField":"lang","as":"language"}},
{$lookup: {from:"languagenames","localField":"language.locale","foreignField":"locale","as":"fulllocale"}},
]).explain()
# 4 ms 😲
- Qué idioma base es el que más hashtags usa en sus tuits?
Planteamiento: “sum del size de los arrays previo filtrado”
db.tweets.aggregate([
{$group: {_id:"$user.lang", "totalHashtags": {$sum:{$size:"$entities.hashtags"}}}},
{$lookup: {from:"primarydialects","localField":"_id","foreignField":"lang","as":"language"}},
{$lookup: {from:"languagenames","localField":"language.locale","foreignField":"locale","as":"fulllocale"}},
{$project:{"language":0}},
{$sort:{"totalHashtags":-1}}
])
- Cómo podemos saber si los tuiteros hispanohablantes interactúan más en las noches?
- Breakdown por lenguaje y cerrando la búsqueda a las 20h ⭐⭐
db.tweets.aggregate([ { $group: { _id: { "lang": "$user.lang", "hour": { $substr: ["$created_at", 11, 2] } }, "counter": { $count: {} } } }, { $match: { "_id.hour": "20" } }, { $sort: { "counter": -1 } } ]); - Usando regexp y con ellas hacer match de horas [19h, 20h y en adelante] ⭐⭐⭐⭐
db.tweets.aggregate([ { $lookup: { from: "primarydialects", "localField": "user.lang", "foreignField": "lang", "as": "language" } }, { $lookup: { from: "languagenames", "localField": "language.locale", "foreignField": "locale", "as": "fulllocale" } }, { $match: { "user.lang": 'es', "created_at": /^[A-Z]+[a-z]{1,2}\s+[A-Z]+[a-z]{1,2}\s+[0-9]{1,2}\s+([1]+[9]|[2]+[0-3])+:+[0-5]+[0-9]+:+[0-5]+[0-9].........../ } }, { $group: { _id: "$fulllocale.languages", "conteo": { $count: {} } } } ]) - Crear variable artificial para dividir horas y a través de la cual agrupar ⭐⭐⭐⭐⭐
db.tweets.aggregate([ { $match: { "user.lang": "es" } }, { $project: { "hora": { $substr: ["$created_at", 11, 8] } } }, { $project: { "team": { $cond: { if: { $and: [ { $gte: [{ $toInt: { $substr: ["$hora", 0, 2] } }, 6] }, { $lte: [{ $toInt: { $substr: ["$hora", 0, 2] } }, 18] }] }, then: "Mañaneros", else: "Nocheros" } } } }, { $group: { _id: "$team", "Twits": { $count: {} } } } ]); - Agrupar por lang y por substring de hora ⭐⭐⭐
db.tweets.aggregate([ { $group: { _id: { "lang": "$user.lang", "hour": { $substr: ["$created_at", 11, 2] } }, "counter": { $count: {} } } }, { $match: { "_id.lang": "es" } }, { $sort: { "counter": -1 } } ]); - Extrayendo la parte de hora en campo created_at y convirtiendo a int ⭐⭐⭐⭐
db.tweets.aggregate([
{ $project : {
text : 1,
'user.lang' : 1,
date_array : { $split: [ "$created_at", " " ]}
}
},
{$addFields: {
hora_raw : {$arrayElemAt: [ "$date_array", 3 ]}
}
},
{$addFields : {
hora_num_str: {
$replaceAll: { input : '$hora_raw', find : ":", replacement : '' }
}
}
},
{$addFields :{
hora_num: { $toInt: "$hora_num_str" }
}
},
{ $match : { $or: [ { hora_num: { $lt: 30000 } }, { hora_num: {$gt : 195959} } ] }},
{$project : {
_id : 0,
hora_num : 1,
"user.lang":1
}
},
{$group:{_id:{"lang":"$user.lang"}, "cuantos":{$count:{}}}}
])
- Cómo podemos saber de dónde son los tuiteros que más tiempo tienen en la plataforma?
- Sobreescribir el campo created_at SOLO DURANTE EL PIPELINE, y ordenar ⭐⭐ - los resultados están expresados en términos de IDs 👎
db.tweets.aggregate([ { $addFields: { "user.created_at": { "$toDate": "$user.created_at" } } }, { $project: { "user.created_at": 1, "user.time_zone": 1 } }, { $sort: { "user.created_at": 1 } } ]); - Armar la fecha con extracción de partes individuales, join con una BD externa de meses, reensamblar fecha con componentes individuales y ordernar ⭐⭐⭐⭐ - uso de la base externa quizá no era necesario ```javascript db.months.insertMany([ { month: “Jan”, order: “01” }, { month: “Feb”, order: “02” }, { month: “Mar”, order: “03” }, { month: “Apr”, order: “04” }, { month: “May”, order: “05” }, { month: “Jun”, order: “06” }, { month: “Jul”, order: “07” }, { month: “Aug”, order: “08” }, { month: “Sep”, order: “09” }, { month: “Oct”, order: “10” }, { month: “Nov”, order: “11” }, { month: “Dec”, order: “12” } ]);
db.tweets.aggregate([ { $project: { “month”: { $substr: [“$user.created_at”, 4, 3] }, “day”: { $substr: [“$user.created_at”, 8, 2] }, “year”: { $substr: [“$user.created_at”, 26, 4] }, “user.screen_name”: 1 } }, { $lookup: { from: “months”, localField: “month”, foreignField: “month”, as: “order” } }, { $unwind: “$order” }, { $project: { “date”: { $concat: [“$year”, “-“, “$order.order”, “-“, “$day”] }, “user.screen_name”: 1, “user.time_zone”: 1 } }, { $sort: { “date”: 1 } }, { $project: { “_id”: 0, “user.screen_name”: 1, “date”: 1 } }, { $limit: 5 } ]);
7. En intervalos de 7:00:00pm a 6:59:59am y de 7:00:00am a 6:59:59pm, de qué paises la mayoría de los tuits?
- $lookup de colecciones de lenguajes/idiomas, match con regexp de created at, agrupación por timezone, y conteo - ⭐⭐ - _hubiera sido mejor en un solo query ambos intervalos_
```javascript
# Esto es para el intervalo 0700 a 1800
db.tweets.aggregate([
{$lookup:{from:"primarydialects","localField":"user.lang","foreignField":"lang","as":"language"}},
{$lookup:{from:"languagenames","localField":"language.locale","foreignField":"locale","as":"fulllocale"}},
{$match:{created_at:{$regex:/[a-z]{3}.[a-z]{3}.[0-9]{2}.(07|08|09|10|11|12|13|14|15|16|17|18).*/i}}},
{$group:{_id:"$user.time_zone",count:{$sum:1}}}
]).sort({"count":-1})
- Conversión a int de created_at y $sortByCount ⭐⭐⭐⭐⭐:
db.tweets.aggregate([
{ $project : {
'user.time_zone' : 1,
date_array : { $split: [ "$created_at", " " ]}
}
},
{$addFields: {
hora_raw : {$arrayElemAt: [ "$date_array", 3 ]}
}
},
{$addFields : {
hora_num_str: {
$replaceAll: { input : '$hora_raw', find : ":", replacement : '' }
}
}
},
{$addFields :{
hora_num: { $toInt: "$hora_num_str" }
}
},
{ $match : { $or: [ { hora_num: { $gt: 70000 } }, { hora_num: {$lt : 185959} } ] }},
{ $sortByCount : "$user.time_zone" }
])
- De qué país son los tuiteros más famosos de nuestra colección?
- Seleccionar con project, ordenar por friends_count (cuestionable porque está el campo followers_count) y mostrar el top N
- planteamiento cuestionable porque hay N tuits de 1 usuario y cada tuit en tiempo T tiene variables de usuario que otro tuit del mismo usuario en tiempo T+10
- Nadie lo hizo así…ni yo 🤣
🧰 Tarea 🧰
- Ejercicios 4 al 6 arriba
- Valor: 8/20 (i.e. 5 puntos del total de 20 que valen todas las tareas - la tarea anterior valía 5)
- Deadline: Jueves 23, 23:59:59
- Método de entrega: Archivo MD o JS en repo de Github
Extracción de Datos de APIs con MongoDB
Las APIs son programitas que corren en servidores y que generalmente ejecutan las 4 operaciones básicas sobre BD:
- CREATE
- RETRIEVE
- UPDATE
- DELETE
En conjunto estas operaciones las llamamos CRUD.
En el 2000 a Roy Felding se le ocurrió que estos “verbos” se parecían un buen a los “verbos” del protocolo HTML:
- CREATE
- GET
- POST
- DELETE
Y desarrolló un protocolo encima de HTTP para poder desarrollar servicios web que “hablaran HTTP de forma nativa”.
Y como suele pasar, un chico de licenciatura le puso en la torre a DECADAS de estándares y desarrollos empresariales, de revisiones, estándares, working groups y otras formas de no hacer las cosas en la búsqueda de INTEROPERABILIDAD DE SISTEMAS.
Cómo funciona? Así:
Y usando los verbos HTTP así:
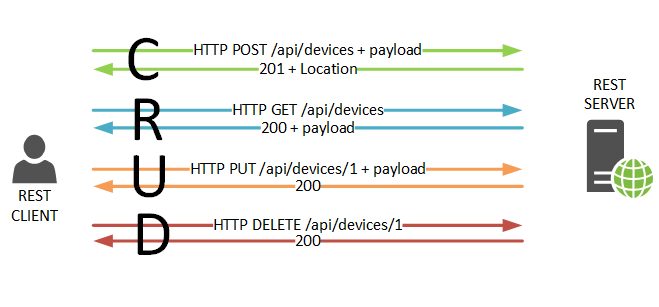
Vamos ahora a conectarnos al APILegslativo a través de un cliente externo para probar:
- Entrar a APILegislativo.
- Seguir las instrucciones para login o registro.
- Asegurarnos de que estamos guardando el token en algún lado para no perderlo.
- Bajar de aquí el Postman
- Checar los endpoints que podemos consultar con el API en https://backend.apilegislativo.com:5000/doc/
- Entrar el URL https://api.apilegislativo.com/iniciativa/aprobada EN EL CAMPO
URLDENTRO DE POSTMAN. - Crear un header HTTP que se llame Authorization.
- Asignarle el valor del
id_token. - Invocar el API
Ya que comprobamos que si se puede conectar, entonces hagamos lo mismo pero con un pequeño script de Python:
import requests
import pymongo
url = "https://api.apilegislativo.com/iniciativa/aprobada/"
payload={}
headers = {
'Authorization': 'eyJraWQiOiIwbVhrbzR4bDBtOTFUOUMxaFNHbCtsZmJCY3VMdVVFQjFmQWxacUtMMFVNPSIsImFsZyI6IlJTMjU2In0.eyJhdF9oYXNoIjoiQW1Gb1E5TUY4a0xpUFQzWklnUmJOQSIsInN1YiI6IjhjMjFjMjc2LTk5NGEtNGI3ZC05NTYxLTgxYjU1YmY3MDNkMiIsImF1ZCI6IjUxMWN1YTRsdTRrYW9zdW9qZmo5NDhmOTB0IiwiZW1haWxfdmVyaWZpZWQiOnRydWUsImV2ZW50X2lkIjoiYjlhMWQ3OTYtZTAyMy00ZDk1LTlkZDktOGNhMjFjMDdhNTUxIiwidG9rZW5fdXNlIjoiaWQiLCJhdXRoX3RpbWUiOjE2MzIwMTU5OTEsImlzcyI6Imh0dHBzOlwvXC9jb2duaXRvLWlkcC51cy1lYXN0LTEuYW1hem9uYXdzLmNvbVwvdXMtZWFzdC0xX2RSM0FaOE8ybyIsImNvZ25pdG86dXNlcm5hbWUiOiI4YzIxYzI3Ni05OTRhLTRiN2QtOTU2MS04MWI1NWJmNzAzZDIiLCJleHAiOjE2MzIwMzAzOTEsImlhdCI6MTYzMjAxNTk5MSwiZW1haWwiOiJqZXN1c0Bzb2NpZWRhdC5vcmcifQ.TRF68Wkhtsr5Bs0ByS91aKBLWLeLob8NO4DjSnLZkiKyVTGa5NS-cVfolPcvUqNpaanuJ6s3CbXZjFoc6lKPNrMB40KrZtA4TlZompYnAstuSNGzaoTMtV4lgyZUQE3AyZ_or76EzBowJyOynUmQDVDwP-FxKE-hKgl92A1C-0aqW8YrunGjvw_zaAD1SypfslxFL21mLcAMzM7ADiHUEp9BaZ5uTdsRxqzSa56FC2Txs0S1anhm_h2uIN2WDQCtZpm6QS8ta1yQ0OtIVMpwJuNQTriTLW2RX8Mo80d8pUIGQhKcZi81oyt2uy5kMCD6WYIw-w9f-6RLQTskyowC_w'
}
response = requests.request("GET", url, headers=headers, data=payload)
myclient = pymongo.MongoClient("mongodb://192.168.68.112:27017/") # similar a ejecutar mongosh
mydb = myclient["apilegislativo"] # == use apilegislativo
mycol = mydb["iniciativasaprobadas"] # == db.iniciativasaprobadas...
iniciativas = response.json()
x = mycol.insert_many(iniciativas["iniciativas"]) # find({"iniciativas:{$exists:true}"})
Expliquemos línea por línea:
- importamos librerías que vamos a usar
- Creamos una variable con el URL del endpoint del API al cual vamos a lanzar la petición
- Creamos un dict con el payload (que va vacío porque este endpoint no admite parámetros)
- Creamos otro dict con los headers. Aquí solo va 1 header llamado Authorization y cuyo valor es el
id_tokenque extrajimos del proceso de login arriba - mandamos llamar el API con el método
requests.request, y asignando el “verbo”GET. Al terminar de ejecutarse esta línea ya tenemos la respuesta del API dentro del objetoresponse - Creamos un client de MongoDB, es decir, un objetito que nos permitirá conectarnos a la BD local. Uds pongan obviamente su IP address o su localhost.
mydb = myclient["apilegislativo"]es exactamente lo mismo queuse apilegislativomycol = mydb["iniciativasaprobadas"]es exactamente lo mismo quedb.iniciativasaprobadas- convertimos el contenido de
responseen formato JSON con el métodojson()y lo guardamos en la variniciativas. - insertamos el arreglo de iniciativas en la colección
iniciativasaprobadas- NO SIN ANTES EXTRAER el elemento que nos interesa insertar.
- Es IMPORTANTÍSIMO primero explorar como nos regresa el objeto el API porque puede ser un solo objeto sin ningún atributo mas que un arreglo de documentos, y entonces el
insert_many()va a fallar porque espera un arreglo cuando le estamos mandando 1 solo elemento