nosql-4-ds
NoSQL Databases 4 Data Science
MonetDB
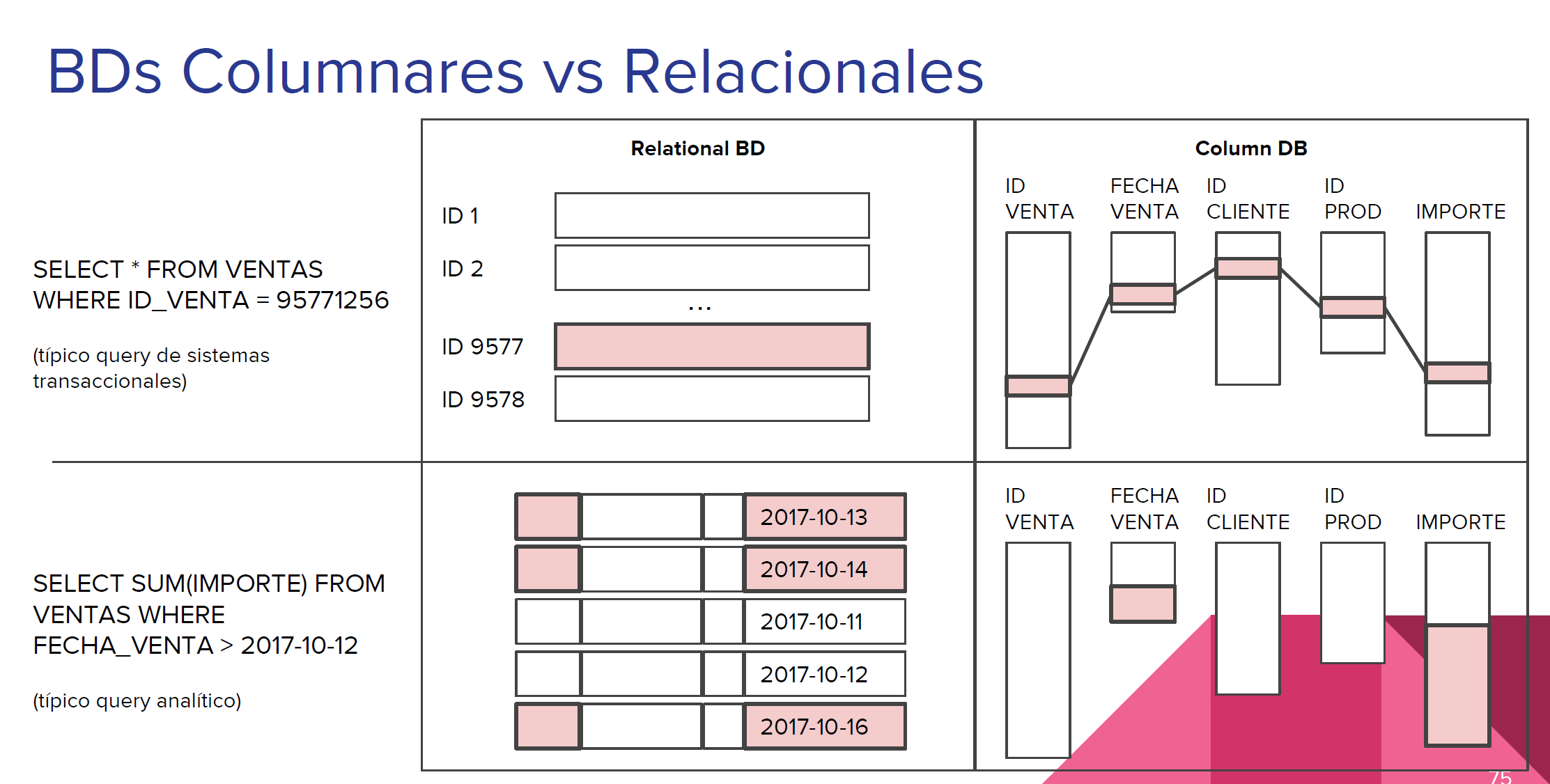
MonetDB es una base de datos columnar.
Recordemos la arquitectura completa de una solución de data lake:

Ya hemos visto que MongoDB está generalmente entre una API y nuestro lake, e hicimos nuestro 1er ETL donde extrajimos datos del APILegislativo y los metimos en nuestro MongoDB de nuestra infraestructura (de momento, local).
Ahora veremos MonetDB. MonetDB es una BD columnar.
Las BDs columnares son buenas para leer, malonas para escribir.
Las BDs columnares generalmente son el destino final de “cubos de datos”
Los cubos de datos son como las vistas.
Recuerdan la BD de Sakila del semestre pasado?

Recuerdan que cuando tenemos queries analíticos complejos, o que generan mucha carga en la BD, recurríamos a las “vistas”?
Bueno…
➡️Cuando las BDs relacionales no son suficientes (ni con índices), las vistas las llevamos a BDs columnares.
Cómo funcionan?
Recordemos el siguiente apunte:
Vamos a utilizar JSON para representar el 1er registro de la tabla film y category de la BD Sakila:
film: {
film_id:1,
title:"ACADEMY DINOSAUR",
description:"A Epic Drama of a Feminist And a Mad Scientist who must Battle a Teacher in The Canadian Rockies",
release_year:2006,
language_id:1,
original_language_id:null,
rental_duration:6,
rental_rate:0.99,
length:86,
replacement_cost:20.99,
rating:{"PG"},
last_update:"2006-02-15 05:03:42",
special_features:{"Deleted Scenes","Behind the Scenes"},
}
category:[
{category_id:1, name:"Action"
{category_id:2, name:"Animation"},
{category_id:3, name:"Children"},
{category_id:4, name:"Classics"},
{category_id:5, name:"Comedy"}
]
Si quisiéramos obtener el promedio de length de todo nuestro catálogo de películas, tendríamos que recorrer renglón por renglón, registro por registro, acumulando y al final dividiendo para obtener el promedio.
Aunque no estamos viajando a otra tabla debido a un join o algo así, de todos modos recorrer toda la tabla amerita un full table scan, que es de las operaciones más costosas en BD, con una running time de O(N).
Si agregamos un join al problema, por ejemplo, si queremos sacar el num de actores por categoría de película, tendremos que hacer lo siguiente:
select c."name" , count(a.actor_id)
from actor a join film_actor fa using (actor_id)
join film f using (film_id)
join film_category fc using (film_id)
join category c using (category_id)
group by c."name";
Si representáramos en JSON estos viajes, terminaríamos con un documento bastante complejo, y dado que no tenemos where, tendríamos que recorrer tabla por tabla, renglón por renglón, matcheando tanto la condición del join como las otras condiciones que tuviéramos, alrededor de O(N)*M tablas.
Ahora imaginemos en JSON, en formato columnar, las mismas tablas:
film_titles:[
1:"ACADEMY DINOSAUR",
2:"ACE GOLDFINGER",
3:"ADAPTATION HOLES",
4:"AFFAIR PREJUDICE",
5:"AFRICAN EGG",
6:"AGENT TRUMAN",
7:"AIRPLANE SIERRA",
8:"AIRPORT POLLOCK",
9:"ALABAMA DEVIL",
10:"ALADDIN CALENDAR"
]
film_lengths:[
1:86,
2:48,
3:50,
4:117,
5:130,
6:169,
7:62,
8:54,
9:114,
10:63
]
film_rental_rate:[
1:0.99,
2:4.99,
3:2.99,
4:2.99,
5:2.99,
6:2.99,
7:4.99,
8:4.99,
9:2.99,
10:4.99
]
PERO luego las BDs columnares implementan unos algoritmos de compresión para reducir estas estructuras a algo como esto:
film_lengths_values:[
1:86,
2:48,
3:50,
4:117,
5:130,
6:169,
7:62,
8:54,
9:114,
10:63
]
film_rental_rate:[
1:0.99,
2:4.99,
3:2.99,
4:->2,
5:->2,
6:->3,
7:->2,
8:->2,
9:->3,
10:->2
]
En la columna film_rental estamos reemplazando valores repetidos por apuntadores, que ocupan menos espacio que un valor y nos permite justo esta compresión.
Teniendo este tipo de estructuras, entonces los queries analíticos como el de abajo, aunque deben hacer igual un full table scan, el running time es O(N)*M, donde la N es un num de registros muchísimo más reducido que en una BD relacional, y el num de tablas involucradas M también podemos mantenerla reducida.
select avg(f.rental_rate) from film f;
Cómo se construyen las BDs columnares?
Por dentro, las BDs columnares son archivos que se construyen de la siguiente forma:

Cada par de ID y valor es 1 solo archivo.
Posterior a la creación de estos archivos, viene la compresión.
Todos los algoritmos de compresión computacionales consiste en hacer una tabla de pares llave-valor, y los valores repetidos reemplazarlos por las llaves.
Idóneamente, las llaves serán enteros pequeñísimos, usualmente 2 a 4 bits, por lo que su búsqueda terminará siendo eficiente, y ocuparán mucho menos espacio que el dato real legible para los humanos (8 bits mínimo).
Por ejemplo, el algoritmo zip:
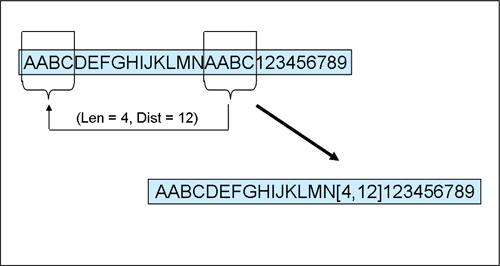
En general, entre más secuencias de caracteres repetidos tengamos en un archivo de texto, más eficiente será la compresión.
Por eso comprimir archivos binarios no sale tan eficiente.
Igual con las BDs columnares.
Comprimir una sola tabla con columnas con poca varianza resultará en eficiencias modestas en los queries analíticos.
Por eso en lugar de meter tabla por tabla a una BD columnar, mejor insertamos una Big Table!
⚠️Y es por esta misma razón que en las BDs columnares las operaciones de INSERT, DELETE o UPDATE o no son soportadas, o son parcialmente soportadas, o tardan muchísimo más que en una BD relacional⚠️
Qué puedo poner en una columnar?
Estas son las formas de BDs que podemos meter en una BD columnar. Todos estos son “esquemas de base de datos para data warehousing”, es decir, formas de acomodar los datos resultado de un querisote analítico para su almacenamiento y consulta constante.
Esquema de estrella

Esquema de snowflake

Esquema de Big Table

Dado el abaratamiento del storage y el poder de cómputo, el esquema preferido para hacer un datawarehouse con una BD columnar es el esquema de Big Table.
Cómo podemos construir una Big Table desde una BD relacional?
select *
from actor a join film_actor fa using (actor_id)
join film f using (film_id)
join film_category fc using (film_id)
join category c using (category_id)
join inventory i using (film_id)
join rental r using (inventory_id)
join payment p using (rental_id);
Este query está haciendo join en 7 tablas, y forzosamente, al hacer join, dadas las cardinalidades de las relaciones, tendremos datos repetidos, y por tanto se vuelve candidato perfecto para formar un esquema Big Table y por tanto, se volverá bastante eficiente guardarlo en una BD columnar.
rental_id|inventory_id|film_id|category_id|actor_id|first_name |last_name |last_update |last_update |title |description |release_year|language_id|original_language_id|rental_duration|rental_rate|length|replacement_cost|rating|last_update |special_features |fulltext |last_update |name |last_update |store_id|last_update |rental_date |customer_id|return_date |staff_id|last_update |payment_id|customer_id|staff_id|amount|payment_date |
---------+------------+-------+-----------+--------+-----------+------------+-------------------+-------------------+----------------------+--------------------------------------------------------------------------------------------------------------------+------------+-----------+--------------------+---------------+-----------+------+----------------+------+-------------------+--------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------+-----------+-------------------+--------+-------------------+-------------------+-----------+-------------------+--------+-------------------+----------+-----------+--------+------+-------------------+
76| 3021| 663| 4| 90|SEAN |GUINESS |2006-02-15 04:34:33|2006-02-15 05:05:03|PATIENT SISTER |A Emotional Epistle of a Squirrel And a Robot who must Confront a Lumberjack in Soviet Georgia | 2006| 1| | 7| 0.99| 99| 29.99|NC-17 |2006-02-15 05:03:42|{Trailers,Commentaries} |'confront':14 'emot':4 'epistl':5 'georgia':19 'lumberjack':16 'must':13 'patient':1 'robot':11 'sister':2 'soviet':18 'squirrel':8 |2006-02-15 05:07:09|Classics |2006-02-15 04:46:27| 2|2006-02-15 05:09:17|2005-05-25 11:30:37| 1|2005-06-03 12:00:37| 2|2006-02-15 21:30:53| 1| 1| 1| 2.99|2005-05-25 11:30:37|
76| 3021| 663| 4| 74|MILLA |KEITEL |2006-02-15 04:34:33|2006-02-15 05:05:03|PATIENT SISTER |A Emotional Epistle of a Squirrel And a Robot who must Confront a Lumberjack in Soviet Georgia | 2006| 1| | 7| 0.99| 99| 29.99|NC-17 |2006-02-15 05:03:42|{Trailers,Commentaries} |'confront':14 'emot':4 'epistl':5 'georgia':19 'lumberjack':16 'must':13 'patient':1 'robot':11 'sister':2 'soviet':18 'squirrel':8 |2006-02-15 05:07:09|Classics |2006-02-15 04:46:27| 2|2006-02-15 05:09:17|2005-05-25 11:30:37| 1|2005-06-03 12:00:37| 2|2006-02-15 21:30:53| 1| 1| 1| 2.99|2005-05-25 11:30:37|
76| 3021| 663| 4| 37|VAL |BOLGER |2006-02-15 04:34:33|2006-02-15 05:05:03|PATIENT SISTER |A Emotional Epistle of a Squirrel And a Robot who must Confront a Lumberjack in Soviet Georgia | 2006| 1| | 7| 0.99| 99| 29.99|NC-17 |2006-02-15 05:03:42|{Trailers,Commentaries} |'confront':14 'emot':4 'epistl':5 'georgia':19 'lumberjack':16 'must':13 'patient':1 'robot':11 'sister':2 'soviet':18 'squirrel':8 |2006-02-15 05:07:09|Classics |2006-02-15 04:46:27| 2|2006-02-15 05:09:17|2005-05-25 11:30:37| 1|2005-06-03 12:00:37| 2|2006-02-15 21:30:53| 1| 1| 1| 2.99|2005-05-25 11:30:37|
76| 3021| 663| 4| 20|LUCILLE |TRACY |2006-02-15 04:34:33|2006-02-15 05:05:03|PATIENT SISTER |A Emotional Epistle of a Squirrel And a Robot who must Confront a Lumberjack in Soviet Georgia | 2006| 1| | 7| 0.99| 99| 29.99|NC-17 |2006-02-15 05:03:42|{Trailers,Commentaries} |'confront':14 'emot':4 'epistl':5 'georgia':19 'lumberjack':16 'must':13 'patient':1 'robot':11 'sister':2 'soviet':18 'squirrel':8 |2006-02-15 05:07:09|Classics |2006-02-15 04:46:27| 2|2006-02-15 05:09:17|2005-05-25 11:30:37| 1|2005-06-03 12:00:37| 2|2006-02-15 21:30:53| 1| 1| 1| 2.99|2005-05-25 11:30:37|
573| 4020| 875| 15| 142|JADA |RYDER |2006-02-15 04:34:33|2006-02-15 05:05:03|TALENTED HOMICIDE |A Lacklusture Panorama of a Dentist And a Forensic Psychologist who must Outrace a Pioneer in A U-Boat | 2006| 1| | 6| 0.99| 173| 9.99|PG |2006-02-15 05:03:42|{Commentaries,Deleted Scenes,Behind the Scenes} |'boat':22 'dentist':8 'forens':11 'homicid':2 'lacklustur':4 'must':14 'outrac':15 'panorama':5 'pioneer':17 'psychologist':12 'talent':1 'u':21 'u-boat':20 |2006-02-15 05:07:09|Sports |2006-02-15 04:46:27| 2|2006-02-15 05:09:17|2005-05-28 10:35:23| 1|2005-06-03 06:32:23| 1|2006-02-15 21:30:53| 2| 1| 1| 0.99|2005-05-28 10:35:23|
573| 4020| 875| 15| 131|JANE |JACKMAN |2006-02-15 04:34:33|2006-02-15 05:05:03|TALENTED HOMICIDE |A Lacklusture Panorama of a Dentist And a Forensic Psychologist who must Outrace a Pioneer in A U-Boat | 2006| 1| | 6| 0.99| 173| 9.99|PG |2006-02-15 05:03:42|{Commentaries,Deleted Scenes,Behind the Scenes} |'boat':22 'dentist':8 'forens':11 'homicid':2 'lacklustur':4 'must':14 'outrac':15 'panorama':5 'pioneer':17 'psychologist':12 'talent':1 'u':21 'u-boat':20 |2006-02-15 05:07:09|Sports |2006-02-15 04:46:27| 2|2006-02-15 05:09:17|2005-05-28 10:35:23| 1|2005-06-03 06:32:23| 1|2006-02-15 21:30:53| 2| 1| 1| 0.99|2005-05-28 10:35:23|
573| 4020| 875| 15| 85|MINNIE |ZELLWEGER |2006-02-15 04:34:33|2006-02-15 05:05:03|TALENTED HOMICIDE |A Lacklusture Panorama of a Dentist And a Forensic Psychologist who must Outrace a Pioneer in A U-Boat | 2006| 1| | 6| 0.99| 173| 9.99|PG |2006-02-15 05:03:42|{Commentaries,Deleted Scenes,Behind the Scenes} |'boat':22 'dentist':8 'forens':11 'homicid':2 'lacklustur':4 'must':14 'outrac':15 'panorama':5 'pioneer':17 'psychologist':12 'talent':1 'u':21 'u-boat':20 |2006-02-15 05:07:09|Sports |2006-02-15 04:46:27| 2|2006-02-15 05:09:17|2005-05-28 10:35:23| 1|2005-06-03 06:32:23| 1|2006-02-15 21:30:53| 2| 1| 1| 0.99|2005-05-28 10:35:23|
573| 4020| 875| 15| 44|NICK |STALLONE |2006-02-15 04:34:33|2006-02-15 05:05:03|TALENTED HOMICIDE |A Lacklusture Panorama of a Dentist And a Forensic Psychologist who must Outrace a Pioneer in A U-Boat | 2006| 1| | 6| 0.99| 173| 9.99|PG |2006-02-15 05:03:42|{Commentaries,Deleted Scenes,Behind the Scenes} |'boat':22 'dentist':8 'forens':11 'homicid':2 'lacklustur':4 'must':14 'outrac':15 'panorama':5 'pioneer':17 'psychologist':12 'talent':1 'u':21 'u-boat':20 |2006-02-15 05:07:09|Sports |2006-02-15 04:46:27| 2|2006-02-15 05:09:17|2005-05-28 10:35:23| 1|2005-06-03 06:32:23| 1|2006-02-15 21:30:53| 2| 1| 1| 0.99|2005-05-28 10:35:23|
573| 4020| 875| 15| 36|BURT |DUKAKIS |2006-02-15 04:34:33|2006-02-15 05:05:03|TALENTED HOMICIDE |A Lacklusture Panorama of a Dentist And a Forensic Psychologist who must Outrace a Pioneer in A U-Boat | 2006| 1| | 6| 0.99| 173| 9.99|PG |2006-02-15 05:03:42|{Commentaries,Deleted Scenes,Behind the Scenes} |'boat':22 'dentist':8 'forens':11 'homicid':2 'lacklustur':4 'must':14 'outrac':15 'panorama':5 'pioneer':17 'psychologist':12 'talent':1 'u':21 'u-boat':20 |2006-02-15 05:07:09|Sports |2006-02-15 04:46:27| 2|2006-02-15 05:09:17|2005-05-28 10:35:23| 1|2005-06-03 06:32:23| 1|2006-02-15 21:30:53| 2| 1| 1| 0.99|2005-05-28 10:35:23|
1185| 2785| 611| 4| 152|BEN |HARRIS |2006-02-15 04:34:33|2006-02-15 05:05:03|MUSKETEERS WAIT |A Touching Yarn of a Student And a Moose who must Fight a Mad Cow in Australia | 2006| 1| | 7| 4.99| 73| 17.99|PG |2006-02-15 05:03:42|{Deleted Scenes,Behind the Scenes} |'australia':19 'cow':17 'fight':14 'mad':16 'moos':11 'musket':1 'must':13 'student':8 'touch':4 'wait':2 'yarn':5 |2006-02-15 05:07:09|Classics |2006-02-15 04:46:27| 1|2006-02-15 05:09:17|2005-06-15 00:54:12| 1|2005-06-23 02:42:12| 2|2006-02-15 21:30:53| 3| 1| 1| 5.99|2005-06-15 00:54:12|
1422| 1021| 228| 4| 186|JULIA |ZELLWEGER |2006-02-15 04:34:33|2006-02-15 05:05:03|DETECTIVE VISION |A Fanciful Documentary of a Pioneer And a Woman who must Redeem a Hunter in Ancient Japan | 2006| 1| | 4| 0.99| 143| 16.99|PG-13 |2006-02-15 05:03:42|{Trailers,Commentaries,Behind the Scenes} |'ancient':18 'detect':1 'documentari':5 'fanci':4 'hunter':16 'japan':19 'must':13 'pioneer':8 'redeem':14 'vision':2 'woman':11 |2006-02-15 05:07:09|Classics |2006-02-15 04:46:27| 2|2006-02-15 05:09:17|2005-06-15 18:02:53| 1|2005-06-19 15:54:53| 2|2006-02-15 21:30:53| 4| 1| 2| 0.99|2005-06-15 18:02:53|
1422| 1021| 228| 4| 144|ANGELA |WITHERSPOON |2006-02-15 04:34:33|2006-02-15 05:05:03|DETECTIVE VISION |A Fanciful Documentary of a Pioneer And a Woman who must Redeem a Hunter in Ancient Japan | 2006| 1| | 4| 0.99| 143| 16.99|PG-13 |2006-02-15 05:03:42|{Trailers,Commentaries,Behind the Scenes} |'ancient':18 'detect':1 'documentari':5 'fanci':4 'hunter':16 'japan':19 'must':13 'pioneer':8 'redeem':14 'vision':2 'woman':11 |2006-02-15 05:07:09|Classics |2006-02-15 04:46:27| 2|2006-02-15 05:09:17|2005-06-15 18:02:53| 1|2005-06-19 15:54:53| 2|2006-02-15 21:30:53| 4| 1| 2| 0.99|2005-06-15 18:02:53|
1422| 1021| 228| 4| 94|KENNETH |TORN |2006-02-15 04:34:33|2006-02-15 05:05:03|DETECTIVE VISION |A Fanciful Documentary of a Pioneer And a Woman who must Redeem a Hunter in Ancient Japan | 2006| 1| | 4| 0.99| 143| 16.99|PG-13 |2006-02-15 05:03:42|{Trailers,Commentaries,Behind the Scenes} |'ancient':18 'detect':1 'documentari':5 'fanci':4 'hunter':16 'japan':19 'must':13 'pioneer':8 'redeem':14 'vision':2 'woman':11 |2006-02-15 05:07:09|Classics |2006-02-15 04:46:27| 2|2006-02-15 05:09:17|2005-06-15 18:02:53| 1|2005-06-19 15:54:53| 2|2006-02-15 21:30:53| 4| 1| 2| 0.99|2005-06-15 18:02:53|
1476| 1407| 308| 5| 31|SISSY |SOBIESKI |2006-02-15 04:34:33|2006-02-15 05:05:03|FERRIS MOTHER |A Touching Display of a Frisbee And a Frisbee who must Kill a Girl in The Gulf of Mexico | 2006| 1| | 3| 2.99| 142| 13.99|PG |2006-02-15 05:03:42|{Trailers,Deleted Scenes,Behind the Scenes} |'display':5 'ferri':1 'frisbe':8,11 'girl':16 'gulf':19 'kill':14 'mexico':21 'mother':2 'must':13 'touch':4 |2006-02-15 05:07:09|Comedy |2006-02-15 04:46:27| 1|2006-02-15 05:09:17|2005-06-15 21:08:46| 1|2005-06-25 02:26:46| 1|2006-02-15 21:30:53| 5| 1| 2| 9.99|2005-06-15 21:08:46|
1725| 726| 159| 5| 199|JULIA |FAWCETT |2006-02-15 04:34:33|2006-02-15 05:05:03|CLOSER BANG |A Unbelieveable Panorama of a Frisbee And a Hunter who must Vanquish a Monkey in Ancient India | 2006| 1| | 5| 4.99| 58| 12.99|R |2006-02-15 05:03:42|{Trailers,Behind the Scenes} |'ancient':18 'bang':2 'closer':1 'frisbe':8 'hunter':11 'india':19 'monkey':16 'must':13 'panorama':5 'unbeliev':4 'vanquish':14 |2006-02-15 05:07:09|Comedy |2006-02-15 04:46:27| 1|2006-02-15 05:09:17|2005-06-16 15:18:57| 1|2005-06-17 21:05:57| 1|2006-02-15 21:30:53| 6| 1| 1| 4.99|2005-06-16 15:18:57|
1725| 726| 159| 5| 179|ED |GUINESS |2006-02-15 04:34:33|2006-02-15 05:05:03|CLOSER BANG |A Unbelieveable Panorama of a Frisbee And a Hunter who must Vanquish a Monkey in Ancient India | 2006| 1| | 5| 4.99| 58| 12.99|R |2006-02-15 05:03:42|{Trailers,Behind the Scenes} |'ancient':18 'bang':2 'closer':1 'frisbe':8 'hunter':11 'india':19 'monkey':16 'must':13 'panorama':5 'unbeliev':4 'vanquish':14 |2006-02-15 05:07:09|Comedy |2006-02-15 04:46:27| 1|2006-02-15 05:09:17|2005-06-16 15:18:57| 1|2005-06-17 21:05:57| 1|2006-02-15 21:30:53| 6| 1| 1| 4.99|2005-06-16 15:18:57|
1725| 726| 159| 5| 157|GRETA |MALDEN |2006-02-15 04:34:33|2006-02-15 05:05:03|CLOSER BANG |A Unbelieveable Panorama of a Frisbee And a Hunter who must Vanquish a Monkey in Ancient India | 2006| 1| | 5| 4.99| 58| 12.99|R |2006-02-15 05:03:42|{Trailers,Behind the Scenes} |'ancient':18 'bang':2 'closer':1 'frisbe':8 'hunter':11 'india':19 'monkey':16 'must':13 'panorama':5 'unbeliev':4 'vanquish':14 |2006-02-15 05:07:09|Comedy |2006-02-15 04:46:27| 1|2006-02-15 05:09:17|2005-06-16 15:18:57| 1|2005-06-17 21:05:57| 1|2006-02-15 21:30:53| 6| 1| 1| 4.99|2005-06-16 15:18:57|
1725| 726| 159| 5| 149|RUSSELL |TEMPLE |2006-02-15 04:34:33|2006-02-15 05:05:03|CLOSER BANG |A Unbelieveable Panorama of a Frisbee And a Hunter who must Vanquish a Monkey in Ancient India | 2006| 1| | 5| 4.99| 58| 12.99|R |2006-02-15 05:03:42|{Trailers,Behind the Scenes} |'ancient':18 'bang':2 'closer':1 'frisbe':8 'hunter':11 'india':19 'monkey':16 'must':13 'panorama':5 'unbeliev':4 'vanquish':14 |2006-02-15 05:07:09|Comedy |2006-02-15 04:46:27| 1|2006-02-15 05:09:17|2005-06-16 15:18:57| 1|2005-06-17 21:05:57| 1|2006-02-15 21:30:53| 6| 1| 1| 4.99|2005-06-16 15:18:57|
1725| 726| 159| 5| 41|JODIE |DEGENERES |2006-02-15 04:34:33|2006-02-15 05:05:03|CLOSER BANG |A Unbelieveable Panorama of a Frisbee And a Hunter who must Vanquish a Monkey in Ancient India | 2006| 1| | 5| 4.99| 58| 12.99|R |2006-02-15 05:03:42|{Trailers,Behind the Scenes} |'ancient':18 'bang':2 'closer':1 'frisbe':8 'hunter':11 'india':19 'monkey':16 'must':13 'panorama':5 'unbeliev':4 'vanquish':14 |2006-02-15 05:07:09|Comedy |2006-02-15 04:46:27| 1|2006-02-15 05:09:17|2005-06-16 15:18:57| 1|2005-06-17 21:05:57| 1|2006-02-15 21:30:53| 6| 1| 1| 4.99|2005-06-16 15:18:57|
1725| 726| 159| 5| 21|KIRSTEN |PALTROW |2006-02-15 04:34:33|2006-02-15 05:05:03|CLOSER BANG |A Unbelieveable Panorama of a Frisbee And a Hunter who must Vanquish a Monkey in Ancient India | 2006| 1| | 5| 4.99| 58| 12.99|R |2006-02-15 05:03:42|{Trailers,Behind the Scenes} |'ancient':18 'bang':2 'closer':1 'frisbe':8 'hunter':11 'india':19 'monkey':16 'must':13 'panorama':5 'unbeliev':4 'vanquish':14 |2006-02-15 05:07:09|Comedy |2006-02-15 04:46:27| 1|2006-02-15 05:09:17|2005-06-16 15:18:57| 1|2005-06-17 21:05:57| 1|2006-02-15 21:30:53| 6| 1| 1| 4.99|2005-06-16 15:18:57|
2308| 197| 44| 14| 193|BURT |TEMPLE |2006-02-15 04:34:33|2006-02-15 05:05:03|ATTACKS HATE |A Fast-Paced Panorama of a Technical Writer And a Mad Scientist who must Find a Feminist in An Abandoned Mine Shaft | 2006| 1| | 5| 4.99| 113| 21.99|PG-13 |2006-02-15 05:03:42|{Trailers,Behind the Scenes} |'abandon':23 'attack':1 'fast':5 'fast-pac':4 'feminist':20 'find':18 'hate':2 'mad':14 'mine':24 'must':17 'pace':6 'panorama':7 'scientist':15 'shaft':25 'technic':10 'writer':11|2006-02-15 05:07:09|Sci-Fi |2006-02-15 04:46:27| 1|2006-02-15 05:09:17|2005-06-18 08:41:48| 1|2005-06-22 03:36:48| 2|2006-02-15 21:30:53| 7| 1| 1| 4.99|2005-06-18 08:41:48|
2308| 197| 44| 14| 106|GROUCHO |DUNST |2006-02-15 04:34:33|2006-02-15 05:05:03|ATTACKS HATE |A Fast-Paced Panorama of a Technical Writer And a Mad Scientist who must Find a Feminist in An Abandoned Mine Shaft | 2006| 1| | 5| 4.99| 113| 21.99|PG-13 |2006-02-15 05:03:42|{Trailers,Behind the Scenes} |'abandon':23 'attack':1 'fast':5 'fast-pac':4 'feminist':20 'find':18 'hate':2 'mad':14 'mine':24 'must':17 'pace':6 'panorama':7 'scientist':15 'shaft':25 'technic':10 'writer':11|2006-02-15 05:07:09|Sci-Fi |2006-02-15 04:46:27| 1|2006-02-15 05:09:17|2005-06-18 08:41:48| 1|2005-06-22 03:36:48| 2|2006-02-15 21:30:53| 7| 1| 1| 4.99|2005-06-18 08:41:48|
2308| 197| 44| 14| 74|MILLA |KEITEL |2006-02-15 04:34:33|2006-02-15 05:05:03|ATTACKS HATE |A Fast-Paced Panorama of a Technical Writer And a Mad Scientist who must Find a Feminist in An Abandoned Mine Shaft | 2006| 1| | 5| 4.99| 113| 21.99|PG-13 |2006-02-15 05:03:42|{Trailers,Behind the Scenes} |'abandon':23 'attack':1 'fast':5 'fast-pac':4 'feminist':20 'find':18 'hate':2 'mad':14 'mine':24 'must':17 'pace':6 'panorama':7 'scientist':15 'shaft':25 'technic':10 'writer':11|2006-02-15 05:07:09|Sci-Fi |2006-02-15 04:46:27| 1|2006-02-15 05:09:17|2005-06-18 08:41:48| 1|2005-06-22 03:36:48| 2|2006-02-15 21:30:53| 7| 1| 1| 4.99|2005-06-18 08:41:48|
2308| 197| 44| 14| 18|DAN |TORN |2006-02-15 04:34:33|2006-02-15 05:05:03|ATTACKS HATE |A Fast-Paced Panorama of a Technical Writer And a Mad Scientist who must Find a Feminist in An Abandoned Mine Shaft | 2006| 1| | 5| 4.99| 113| 21.99|PG-13 |2006-02-15 05:03:42|{Trailers,Behind the Scenes} |'abandon':23 'attack':1 'fast':5 'fast-pac':4 'feminist':20 'find':18 'hate':2 'mad':14 'mine':24 'must':17 'pace':6 'panorama':7 'scientist':15 'shaft':25 'technic':10 'writer':11|2006-02-15 05:07:09|Sci-Fi |2006-02-15 04:46:27| 1|2006-02-15 05:09:17|2005-06-18 08:41:48| 1|2005-06-22 03:36:48| 2|2006-02-15 21:30:53| 7| 1| 1| 4.99|2005-06-18 08:41:48|
2363| 3497| 766| 7| 153|MINNIE |KILMER |2006-02-15 04:34:33|2006-02-15 05:05:03|SAVANNAH TOWN |A Awe-Inspiring Tale of a Astronaut And a Database Administrator who must Chase a Secret Agent in The Gulf of Mexico| 2006| 1| | 5| 0.99| 84| 25.99|PG-13 |2006-02-15 05:03:42|{Commentaries,Deleted Scenes,Behind the Scenes} |'administr':14 'agent':20 'astronaut':10 'awe':5 'awe-inspir':4 'chase':17 'databas':13 'gulf':23 'inspir':6 'mexico':25 'must':16 'savannah':1 'secret':19 'tale':7 'town':2 |2006-02-15 05:07:09|Drama |2006-02-15 04:46:27| 1|2006-02-15 05:09:17|2005-06-18 13:33:59| 1|2005-06-19 17:40:59| 1|2006-02-15 21:30:53| 8| 1| 2| 0.99|2005-06-18 13:33:59|
2363| 3497| 766| 7| 67|JESSICA |BAILEY |2006-02-15 04:34:33|2006-02-15 05:05:03|SAVANNAH TOWN |A Awe-Inspiring Tale of a Astronaut And a Database Administrator who must Chase a Secret Agent in The Gulf of Mexico| 2006| 1| | 5| 0.99| 84| 25.99|PG-13 |2006-02-15 05:03:42|{Commentaries,Deleted Scenes,Behind the Scenes} |'administr':14 'agent':20 'astronaut':10 'awe':5 'awe-inspir':4 'chase':17 'databas':13 'gulf':23 'inspir':6 'mexico':25 'must':16 'savannah':1 'secret':19 'tale':7 'town':2 |2006-02-15 05:07:09|Drama |2006-02-15 04:46:27| 1|2006-02-15 05:09:17|2005-06-18 13:33:59| 1|2005-06-19 17:40:59| 1|2006-02-15 21:30:53| 8| 1| 2| 0.99|2005-06-18 13:33:59|
Instalando MonetDB
Estas instrucciones de instalación son para Ubuntu 18.04 o superior, o Debian.
Deben tener instalado el Ubuntu 18.04 o 20.04 desde la Microsoft Store, o bien una máquina virtual con VirtualBox.
Crear el siguiente archivo con el comando nano:
sudo nano /etc/apt/sources.list.d/monetdb.list
Y poner el contenido del 2o codeblockde abajo. 👀OJO👀 deben reemplazar la palabra suite con el nombre del release de ubuntu. Eso lo pueden saber con la salida del comando
lsb_release -cs
Para los que tienen Ubuntu 20.04, la salida será focal. PAra los que tienen Ubuntu 18.04 será bionic. No olviden quitar los corchetes!
El contenido del archivo debe ser:
deb https://dev.monetdb.org/downloads/deb/ [suite] monetdb
deb-src https://dev.monetdb.org/downloads/deb/ [suite] monetdb
El siguiente comando instalará la llave pública del monetdb. Esto es para comprobar que la instalación es válida.
sudo wget --output-document=/etc/apt/trusted.gpg.d/monetdb.gpg https://www.monetdb.org/downloads/MonetDB-GPG-KEY.gpg
Ahora vamos a validar la instalación de la llave con:
sudo apt-key finger
La llave para el entry /etc/apt/trusted.gpg.d/monetdb.gpg deberá ser 8289 A5F5 75C4 9F50 22F8 EE20 F654 63E2 DF0E 54F3.
En Ubuntu 18.04 es posible que tengamos que instalar un paquete de certificados:
sudo apt install ca-certificates
Después de esto ya se puede instalar el MonetDB:
sudo apt update
sudo apt install monetdb5-sql monetdb-client
Contrario a PostgreSQL, los Ubuntu que corren dentro de Windows no soportan que los usuarios definan servicios, osea, que haya programas que arranquen junto con el sistema operativo, porque pues este Ubuntu no “arranca” en realidad.
Por eso tenemos que iniciar el MonetDB a pata 🐾.
Cómo funcionan las BDs columnares?
Funcionan en cluster, básicamente.
Idóneamente debemos tener 1 nodo maestro y 1 o más nodos worker.

Cada nodo worker puede ser de réplica, o de sharding.
En la réplica, 2 nodos tienen la mismita información, en uno se escribe y en otro se lee.
Esta arquitectura en bases de datos relacionales sirve para distribuir la carga entre los sistemas transaccionales y los sistemas de información, es decir, en la fuente de la réplica conectamos nuestros puntos de venta, sistemas de inventario, de marketing, etc, y las herramientas de BI las conectamos a la réplica para que un query mal planeado de cientos de miles de registros no roben recursos a la BD transaccional y nos detengan la operación.

Por otro lado, en el sharding tenemos cierto cacho de la BD en un nodo, y otros cacho en otro, de modo que si un nodo falla, seguimos teniendo disponibilidad de cierta cantidad de registros o datos:
▶️ Pero como todo lo vamos a correr en local, entonces tanto el proceso master y los procesos worker en la misma máquina.
En MonetDB, los nodos worker los llamamos farm.
Vamos a arrancar el MonetDB con los siguientes comandos:
cd ~
mkdir monetdb
mkdir monetdb/farm
monetdbd create monetdb/farm
monetdbd set listenaddr=0.0.0.0 monetdb/farm/
monetdbd start monetdb/farm
Con estos comandos creamos un directorio monetdb/myfarm donde va a vivir nuestra BD.
Luego usamos el comando monetdbd para crear y arrancar el servidor de MonetDB con 1 nodo en su farm.
👀OJO👀 el penúltimo comando le dice a MonetDB que arranque sus procesos de servidor escuchando desde cualquier dirección IP.
Cuando vean comandos de Unix que terminen con una d, seguro son daemon. Si, viene de la palabra demon, pero con este significado:
The term was coined by the programmers at MIT’s Project MAC. According to Fernando J. Corbató, who worked on Project MAC in 1963, his team was the first to use the term daemon, inspired by Maxwell’s demon, an imaginary agent in physics and thermodynamics that helped to sort molecules, stating, “We fancifully began to use the word daemon to describe background processes that worked tirelessly to perform system chores”. Unix systems inherited this terminology. Maxwell’s demon is consistent with Greek mythology’s interpretation of a daemon as a supernatural being working in the background. However, BSD and some of its derivatives have adopted a Christian demon as their mascot rather than a Greek daemon.
Todos los daemon ayudan a correr procesos background en sistemas Unix.
Por ende, TODOS los servidores son ejecutados por daemons.
Una vez arrancado el daemon o el server, podemos crear bases de datos.
Vamos a crear la base de datos VOC. Esta base de datos es el registro naviero de la Vereenigde geoctrooieerde Oostindische Compagnie, o Dutch East India Company para los siglos XVII y XVIII. Si, la misma de “Piratas del Caribe”.

monetdb create voc
monetdb release voc
El comando monetdb sirve para interactuar administrativamente con la BD, para crear objetos y estructuras. ⚠️NO CONFUNDIR CON EL COMANDO monetdbd⚠️, que es el daemon que vimos arriba.
El operador create crea una BD en modo maintenance, es decir, en un área de staging que no es producción, y por tanto no está disponible para conexiones desde fuera, por ejemplo, desde DBeaver.
El operador release libera a producción la BD y ahora si podemos interactuar con ella desde afuera.
Vamos a descargar el ZIP con la BD, crear usuarios y cargar datos a nuestra BD voc. Vamos a hacer esto con el cliente mclient, que nos permite interactuar con MonetDB desde la command line:
mclient -u monetdb -d voc
password: "monetdb"
CREATE USER "voc" WITH PASSWORD 'voc' NAME 'VOC Explorer' SCHEMA "sys";
CREATE SCHEMA "voc" AUTHORIZATION "voc";
ALTER USER "voc" SET SCHEMA "voc";
\q
Lo que estamos haciendo aquí es:
- conectándonos con
mclientcon el usuariomonetdba la BDvoc. El password es igualmonetdb. - creando un usuario con clave
voccon passwdvoccon nombre “VOC Explorer” en el esquemasys, que es el de default, como elpublicen PostgreSQL. En MonetDB es necesario especificar el esquema donde queremos que se alojen los objetos que estamos creando. - creando el esquema
vocy dando autorización al usuariovocpara conectarse. - cambiando el usuario del esquema de default
sysal esquemavoc. - saliendo del
mclientcon el meta-comando\q.
Ahora vamos a reconectarnos con la BD voc con el usuario voc en lugar del usuario administrador monetdb y crear unas tablas de muestra:
mclient -u voc -d voc
password: "voc"
start transaction;
CREATE TABLE test (id int, data varchar(30));
\d
\d test
rollback;
\d
Qué estamos haciendo aquí?
- Nos estamos conectando a la BD
voccon el usuariovoc. - Estamos iniciando una transacción. 👀OJO👀, en MonetDB y en la mayoría de las BDs columnares, los comandos para la creación de objetos SI FORMAN PARTE DE LAS TRANSACCIONES Y POR TANTO PUEDEN REVERSARSE.
- Estamos creando la tabla
testque tiene solo los camposidydata. - El metacommand
\dsignifica describe, y si no recibe argumentos, nos describe la BD e, términos de las tablas que contiene porque ahí estamos parados en este momento. \d testnos describe la tablatestque acabamos de crear, y lo que nos muestra es el DDL que usamos para crear la tabla.- Reversamos la transacción con
rollback;. - Vemos con
\dque la tabla desapareció. En PostgreSQL y la mayoría de las relacionales, un rollback no afecta los comandos estructurales con los que creamos tablas, índices, secuencias, etc.
Vamos ahora a importar la BD que descargamos:
mclient -u voc -d voc < voc_dump.sql
Si queremos cambiarle el password al usuario monetdb podemos usar:
ALTER USER SET UNENCRYPTED PASSWORD 'xxxxxx' USING OLD PASSWORD 'monetdb';
Ejercicio de carga PostgreSQL VS MonetDB
Vamos a poner a MonetDB a jugar carreras VS PostgreSQL para inserción de datos.
Tengo una BD de viajes de Ecobici de 2010 a 2017. ⚠️ Son más de 45 millones de registros, osea alrededor de 18GB ⚠️, entonces para efectos didácticos no conviene que manejen ni intenten cargar esta base completa, por lo que les voy a compartir un subset de 10M de registros.
Para ambos vamos a usar una utilería de carga masiva de DBeaver, mientras que para MonetDB usaremos el comando COPY, que también sirve para carga masiva.
Primero debemos crear tanto en MonetDB como en PostgreSQL la siguiente tabla:
Primero en PostgreSQL:
create schema ecobici;
set search_path to ecobici;
create table ecobici_historico (
genero_usuario VARCHAR(80),
edad_usuario VARCHAR(80),
bici VARCHAR(80),
fecha_retiro VARCHAR(80),
hora_retiro_copy VARCHAR(80),
fecha_retiro_completa VARCHAR(80),
anio_retiro VARCHAR(80),
mes_retiro VARCHAR(80),
dia_semana_retiro VARCHAR(80),
hora_retiro VARCHAR(80),
minuto_retiro VARCHAR(80),
segundo_retiro VARCHAR(80),
ciclo_estacion_retiro VARCHAR(80),
nombre_estacion_retiro VARCHAR(80),
direccion_estacion_retiro VARCHAR(80),
cp_retiro VARCHAR(80),
colonia_retiro VARCHAR(80),
codigo_colonia_retiro VARCHAR(80),
delegacion_retiro VARCHAR(80),
delegacion_retiro_num VARCHAR(80),
fecha_arribo VARCHAR(80),
hora_arribo_copy VARCHAR(80),
fecha_arribo_completa VARCHAR(80),
anio_arribo VARCHAR(80),
mes_arribo VARCHAR(80),
dia_semana_arribo VARCHAR(80),
hora_arribo VARCHAR(80),
minuto_arribo VARCHAR(80),
segundo_arribo VARCHAR(80),
ciclo_estacion_arribo VARCHAR(80),
nombre_estacion_arribo VARCHAR(80),
direccion_estacion_arribo VARCHAR(80),
cp_arribo VARCHAR(80),
colonia_arribo VARCHAR(80),
codigo_colonia_arribo VARCHAR(80),
delegacion_arribo VARCHAR(80),
delegacion_arribo_num VARCHAR(80),
duracion_viaje VARCHAR(80),
duracion_viaje_horas VARCHAR(80),
duracion_viaje_minutos VARCHAR(80)
);
Luego en MonetDB:
En la consola:
monetdb create ecobici
monetdb release ecobici
mclient -u monetdb -d ecobici
password: "monetdb"
Luego dentro del cliente de MonetDB mclient creamos el usuario y el esquema ecobici:
CREATE USER "ecobici" WITH PASSWORD 'ecobici' NAME 'EcoBici Explorer' SCHEMA "sys";
CREATE SCHEMA "ecobici" AUTHORIZATION "ecobici";
ALTER USER "ecobici" SET SCHEMA "ecobici";
\q
Y finalmente entramos con el usuario ecobici que acabamos de crear y creamos la tabla ecobici_historico:
mclient -u ecobici -d ecobici
password: "ecobici"
Ya dentro de mclient, ejecutamos:
create table ecobici_historico (
genero_usuario VARCHAR(80),
edad_usuario VARCHAR(80),
bici VARCHAR(80),
fecha_retiro VARCHAR(80),
hora_retiro_copy VARCHAR(80),
fecha_retiro_completa VARCHAR(80),
anio_retiro VARCHAR(80),
mes_retiro VARCHAR(80),
dia_semana_retiro VARCHAR(80),
hora_retiro VARCHAR(80),
minuto_retiro VARCHAR(80),
segundo_retiro VARCHAR(80),
ciclo_estacion_retiro VARCHAR(80),
nombre_estacion_retiro VARCHAR(80),
direccion_estacion_retiro VARCHAR(80),
cp_retiro VARCHAR(80),
colonia_retiro VARCHAR(80),
codigo_colonia_retiro VARCHAR(80),
delegacion_retiro VARCHAR(80),
delegacion_retiro_num VARCHAR(80),
fecha_arribo VARCHAR(80),
hora_arribo_copy VARCHAR(80),
fecha_arribo_completa VARCHAR(80),
anio_arribo VARCHAR(80),
mes_arribo VARCHAR(80),
dia_semana_arribo VARCHAR(80),
hora_arribo VARCHAR(80),
minuto_arribo VARCHAR(80),
segundo_arribo VARCHAR(80),
ciclo_estacion_arribo VARCHAR(80),
nombre_estacion_arribo VARCHAR(80),
direccion_estacion_arribo VARCHAR(80),
cp_arribo VARCHAR(80),
colonia_arribo VARCHAR(80),
codigo_colonia_arribo VARCHAR(80),
delegacion_arribo VARCHAR(80),
delegacion_arribo_num VARCHAR(80),
duracion_viaje VARCHAR(80),
duracion_viaje_horas VARCHAR(80),
duracion_viaje_minutos VARCHAR(80)
);
Aquí el videito donde utilizamos la utilería de DBeaver para cargar las tablas:
https://user-images.githubusercontent.com/1316464/137060932-9b24eca6-dbd3-442f-bb61-26d463d6fe36.mp4
⚠️ ESTA NO ES LA SOLUCIÓN MÁS ÓPTIMA!
La herramienta que nos da DBeaver NO ES la forma más óptima de hacer cargas masivas a BDs, ni columnares ni relacionales.
La forma más óptima es el comando COPY.
El COPY realiza bastantes optimizaciones tanto del lado de la BD como del sistema operativo para poder realizar estas cargas.
Lamentablemente, son herramientas SÚPER PICKY!
Desde el Lunes en la tarde he intentado echar a andar los COPY del lado de MonetDB y PostgreSQL, sin éxito, pero con los siguientes findings:
En PostgreSQL con Windows 10
- El
COPYpuede ser invocado desde una herramienta SQL como una ventana de DBeaver, o desde la línea de comandos. - Cuando se invoca desde la línea de comandos, se hace en conjunto con el comando
psql, que es el command-line de PostgreSQL, y entonces elcopyse vuelve el metacomando\copy. - La sintaxis general para este caso de ecobici es
copy ecobici_historico from '/ruta/al/archivo/ecobici_2010_2017-final.csv' with csv header. Si esto lo corremos desdepsql, entonces debemos de anteponer el\alcopy- la parte de
with csv headerle dice al copy que la entrada es un archivo CSV y que además la 1a línea tiene los nombres de las columnas.
- la parte de
- Lo invoquemos por donde lo invoquemos, el PostgreSQL hace uso de una función VIEJÍSIMA del sistema operativo llamada
fstat()que sirve para saber si un argumento es archivo o es directorio.- Esta función existe desde los sistemas operativos antecesores del Windows y nunca se ha actualizado porque ya todos los lenguajes de programación tienen sus propias funciones para obtener esta respuesta.
- Esta función, vieja como es, no admite como argumento archvivos gigantes de más de 4GB.
- Este es un bug conocido desde PostgreSQL 10 y apenas se corrigió en PostgreSQL 14.
- Al tratar de ejecutar ese copy, el resultado es
ERROR: could not stat file "'D:/XXX.csv' value too large. - A falta de esto, debimos usar la utilería de DBeaver.
En MonetDB
- La sintaxis del
copyen MonetDB es similar. En general escopy offset 2 into ecobici_historico from '/home/xuxoramos/ecobici_2010_2017-final.csv' on client using delimiters ',',E'\r' null as ' ';- el
offset 2es para indicar que el 1er renglón no lo debemos procesar porque son los encabezados de las columnas. - el
on clientestá delegando autorizaciones y permisos al server en lugar de directo al comandocopy. using delimiters ',',E'\r'es para indicarle que los separadores de los campos son comas, y los separadores de línea es el caracter\r, que significa carriage return.null as ' 'es para indicar que los strings vacíos deben ser considerados nulos.
- el
- Estos comandos son muy picky, y dentro de nuestro archivo, los caracteres especiales como vocales acentuadas, están representadas con la clave unicode
<U+XXXX>, dondeXXXXes una clave en hexadecimal indicando el caracter. Por ejemplo, la delegación “Álvaro Obregón” está dada como<U+00C1>lvaro Obreg<U+00F3>n. - Esta notación confunde al comando
copyde MonetDB, y lo vuelve inoperante, a veces reportando que no existen valores en la columna 41 y línea 1, y a veces en la columna 2 y línea 1. - Encima de esto, el encoding de archivos puede ser un problema. Los archivos de texto, sean CSV o TXT, están llenos de caracteres escondidos que le dan forma. Los caracteres escondidos más comunes son los que representan new line, desafortunadamente son diferentes dependiendo del sistema operativo, y esto también contribuye a que el
copyno procese bien archivos de entrada:\npara Linux y Mac\r\npara Windows 10\rpara Windows 8 para atrás
- Estamos hablando de un archivo de 45M de líneas, así que cualquier intento de arreglar los problemas descritos arriba con
sedoawkresultará en un tiempo de espera bastante largo.
Afortunadamente, en mi otra máquina si funcionó, pero igual con los siguientes caveats:
En PostgreSQL
- Tuve que instalar PostgreSQL 14 en Ubuntu 20.04 sobre Windows
- Este postgresql en Ubuntu se instala sin interfaz gráfica, por lo que hay que:
- Asignarle password al usuario postgres que el instalador crea para Ubuntu
- Asignarle password al usuario postgres que el instalador crea para la base de datos
- Correr el comando
psql -U postgres -h localhost -p 5435 -c "\copy ecobici.ecobici_historico from '/home/xuxoramos/ecobici_2010_2017-final.csv' with csv header;"psql -U postgres -h localhost -p 5435significa “abre una línea de comando conectándonos a la BDpostgrescon el usrpostgresa la máquinalocalhosten el puerto5435-c "\copy...significa “una vez abierto el command-line, manda el resto del comando.
- 👀OJO👀: es importante recordar que estas operaciones requieren mucho espacio, al menos 3x lo que mide el archivo que vamos a pasar por
copy.
Mientras que la utilería de carga masiva de DBeaver tardó alrededor de 18h, la carga masiva con copy tardó:

🔥8 MINUTOS!🔥
Las carreritas
Vamos a ejecutar un query analítico que obtenga el promedio de duración de viajes entre todos los pares de colonias.
En PostgreSQL 🐘
explain analyze select avg(eh.fecha_arribo_completa::timestamp - eh.fecha_retiro_completa::timestamp)::interval
from ecobici_historico eh
group by eh.colonia_retiro , eh.colonia_arribo;
Lo comencé a ejecutar alrededor de las 10 de la mañana. Para las 2h transcurridas aún no terminaba:

Decidí interrumpirlo para intentar reducirlo en carga agregándole un WHERE:
explain analyze select avg(eh.fecha_arribo_completa::timestamp - eh.fecha_retiro_completa::timestamp)::interval
from ecobici_historico eh
where eh.colonia_retiro = 'Cuauhtemoc'
group by eh.colonia_retiro , eh.colonia_arribo;
Con este cambio tardó 1 min 51 seg:

Vamos a ver si le ganamos tantito con un índice sobre colonia_retiro dado que tenemos una condición where:
create index big_data_ecobici_colonia_retiro on ecobici.ecobici_historico_import (
colonia_retiro
);
La creación de índices igual es costosa en una tabla con millones de registros. Esta creación se tardó 2m 18s.

Esta ejecución tardó 1m 50s con un índice en el campo del WHERE.
Le ganamos 1 seg 🤡🤡🤡
La razón de esto es que el query en particular está agrupando por 2 campos, y esto provoca un sequential scan, que es donde está el grueso del tiempo de la consulta.
En general, no es muy efectivo el índice.
En MonetDB 🖼️
El query en MonetDB tiene algunos cambios en sintaxis y no estamos agregando cláusula WHERE porque precisamente deseamos “presumir” las capacidades de las BDs columnares:
select eh.colonia_retiro , eh.colonia_arribo ,
avg(cast(fecha_arribo_completa as timestamp) - cast(eh.fecha_retiro_completa as timestamp))/60 as promedio_duracion
from ecobici_historico eh
group by eh.colonia_retiro , eh.colonia_arribo
order by promedio_duracion desc;

🔥 2.13 seg 🔥

Cómo usamos MonetDB como Data Warehouse?
El uso principal de las BDs columnares es como Data Warehouse.
El Data Warehousing es precisamente jalar de una relacional/transaccional y guardar en una columnar/analítica para formar histórico profundo.
Las características principales del Data Warehousing moderno son:
- Los datos a cargar están en forma de Big Table
- La llave primaria de dicha Big Table es una columna que describe el paso del tiempo (aún cuando no tengamos datos en cierto timeslot)
Allá afuera se van a encontrar aún con gente que usa esquemas de snowflake o star para modelar data warehouses.
Ambos esquemas usan un diseño donde al centro está una tabla de facts junto con las fechas, y decenas de llaves foráneas, y alrededor, exportándoles su llave, decenas de tablas llamadas dimensiones, que son básicamente los objetos de negocio.

👀OJO👀 Fíjense como este esquema se parece un buen a los esquemas relacionales que usualmente tenemos en las BDs relacionales/transaccionales.
Las “dimensiones” son los objetos de negocio.
Los “facts” son los eventos de negocio que combinan uno o más objetos de negocio para describirse.
Y como tal, los “facts” tienen como llave la “dimensión” 🕰️TIEMPO🕰️.
Estos esquemas de dimensional modeling fueron creados por Ralph Kimball en el 96, PERO en ese momento la realidad era muy, muy diferente.
Algunos supuestos de esos años, que ya no son vigentes, son:
- Databases are slow and expensive
- SQL language is limited
- You can never join fact tables because of one to many or many to one joins
- Businesses are slow to change
Entonces, dado que:
- Las bases de datos ya son rápidas y el storage baratísimo
- Y que el SQL ha evolucionado a un lenguaje rico en features y expresiones que, aunque no forman parte del estándar, nos simplifican la vida
- Y que estas restricciones quedan acotadas en las bases de datos relacionales y que ya tenemos otras tantas formas de organizar data
- Y que el mundo startupero ha redefinido la velocidad con la que se operan los negocios
Entonces podemos decir que el trabajo de Kimball es ya poco relevante.
Aunque cientos de ingenieros viejitos en el sector público (y uno que otro del sector privado) les digan que no.
Lo único rescatable que podemos sacar del trabajo de Kimball es el manejo de la dimensión tiempo, que podemos combinar con esquemas modernos de Big Table o One Big Table.
Vamos a utilizar la BD de Northwind para emular la creación de un DWH con la dimensión tiempo:
1. Definir granularidad
Vamos a explorar las tablas centrales de la BD de Northwind para tratar de obtener la frecuencia mínima con la que se crean nuevos registros en ellas.
- Las tablas centrales para el negocio de Northwind, y que además tienen algún campo tipo
dateson:ordersemployees
- En la tabla
orderstenemos que hay un nuevo registro cada .8 díasselect avg(timediff) from (SELECT order_date - lag(order_date) OVER (ORDER BY order_date) as timediff FROM orders o ORDER BY order_date) as t; - En la tabla
employeestenemos que hay un nuevo hire cada 150 díasselect avg(abs(timediff)) from (SELECT hire_date - lag(hire_date) OVER (ORDER BY e.employee_id) as timediff FROM employees e ORDER BY e.employee_id) as t;
Con esto podemos decir que la mínima frecuencia de inserción es de 1 día.
Por tanto, la dimensión time de nuestra BD histórica será diaria:
2. Crear tabla con dimensión tiempo
Del lado de la BD fuente vamos a crear la tabla que representará nuestra dimensión de tiempo.
Vamos a ir a la fecha mínima y máxima de las 2 tablas de arriba:
- En
ordersla mínima deorder_datees 1996-07-04 y el máximo es 1998-05-06 - En
employeesel mínimo dehire_datees 1992-04-01 y el máximo es 1994-11-15
Por tanto, nuestra tabla con la dimensión de tiempo va a ir diario desde 1992-04-01 hasta 1998-05-06.
Esta tabla la vamos a crear del lado de PostgreSQL:
create table time_dimension (
date_axis date primary key,
seq_num serial unique not null
);
insert into time_dimension(date_axis) -- recordemos que para insertar desde un select, omitimos el keyword values
select t.day::date
from generate_series(timestamp '1992-04-01',
timestamp '1998-05-06',
interval '1 day') as t(day);
3. Extraer y hacer join con dimensión de tiempo
Ya con la tabla que nos da el eje de tiempo, podemos hacer las extracciones de toda la BD y hacer un left join con la tabla de tiempo para indicar cuando no hay evento en esa fecha para X o Y objeto de negocio:
select *
from time_dimension td
left outer join orders o on (td.date_axis = o.order_date)
left outer join employees e on (td.date_axis = e.hire_date)
left outer join order_details od using (order_id)
left outer join products p using (product_id)
left outer join categories cat using (category_id)
left outer join suppliers s using (supplier_id)
left outer join shippers sh on (o.ship_via = sh.shipper_id)
left outer join customers cus using (customer_id)
order by td.date_axis;
Algunas notas:
- Por legibilidad, primero hacer el
joinentre la tabla de dimensión de tiempo y las tablas a las que vamos a sujetar a este eje común. - Usar
left outer joinpara permitir nulos, y con esto, saber cuando en una fecha no tenemos ni facts o eventos deemployeesuorders. - Siempre ordenar (de forma
ascodesc) el query.
Pareciera que podemos insertar ya esta tabla de PostgreSQL a MonetDB, pero forzar un mismo eje o dimensión de tiempo en esta big table nos pone demasiados nulos, que además están localizados en un período en específico, y donde además hay poco empalme entre ambos períodos.
Cuando los resultados son así de confusos, es recomendable entonces crear 2 tablas de facts en nuestro DWH. En este caso, vamos a crear una tabla de facts para orders y otra tabla de facts para employees:
select *
from time_dimension td
left outer join orders o on (td.date_axis = o.order_date)
left outer join order_details od using (order_id)
left outer join products p using (product_id)
left outer join categories cat using (category_id)
left outer join suppliers s using (supplier_id)
left outer join shippers sh on (o.ship_via = sh.shipper_id)
left outer join customers cus using (customer_id)
left outer join employees e using (employee_id)
left outer join employee_territories et using (employee_id)
left outer join territories t using (territory_id)
order by td.date_axis;
select *
from time_dimension td
left outer join employees e on (td.date_axis = e.hire_date)
left outer join employee_territories et using (employee_id)
left outer join territories t using (territory_id)
order by td.date_axis;
👀OJO👀 en ambas tablas de facts tenemos info repetida sobre los empleados. Esto es perfectamente normal en el diseño de Big Table, dado que las 2 tablas sirven propósitos analíticos diferentes: mientras que los employees dentro de la 1a tabla son dependientes de order, en la otra tabla de facts los employees son la entidad central y solo los tenemos a ellos.
4. Copiar dichas tablas a MonetDB
Primero debemos crear las tablas para luego escribir estos datos.
Para esto vamos a usar una versión del comando create table que toma como entrada un as select....
create table fact_orders as
select
territory_id,
employee_id,
customer_id,
supplier_id,
category_id,
product_id,
order_id,
date_axis,
seq_num,
order_date,
required_date,
shipped_date,
ship_via,
freight,
ship_name,
ship_address,
ship_city,
ship_region,
ship_postal_code,
ship_country,
p.unit_price as unit_price_in_product,
quantity,
discount,
product_name,
quantity_per_unit,
od.unit_price as unit_price_in_order,
units_in_stock,
units_on_order,
reorder_level,
discontinued,
category_name,
description,
picture,
s.company_name as supplier_company_name,
s.contact_name,
s.contact_title,
s.address as supplier_address,
s.city as supplier_city,
s.region as supplier_region,
s.postal_code,
s.country as supplier_country,
s.phone as supplier_phone,
s.fax as supplier_fax,
s.homepage,
shipper_id,
sh.company_name as shipper_company_name,
sh.phone,
cus.company_name,
cus.contact_name as customer_company_name,
cus.contact_title as customer_contact_title,
cus.address as customer_address,
cus.city as customer_city,
cus.region as customer_region,
cus.postal_code as customer_postal_code,
cus.country as customer_country,
cus.phone as customer_phone,
cus.fax as customer_fax,
e.last_name,
e.first_name,
e.title,
e.title_of_courtesy,
e.birth_date,
e.hire_date,
e.address as employee_address,
e.city as employee_city,
e.region as employee_region,
e.postal_code as employee_postal_code,
e.country as employee_country,
e.home_phone,
e.extension,
e.photo,
e.notes,
e.reports_to,
e.photo_path,
t.territory_description,
t.region_id
from time_dimension td
left outer join orders o on (td.date_axis = o.order_date)
left outer join order_details od using (order_id)
left outer join products p using (product_id)
left outer join categories cat using (category_id)
left outer join suppliers s using (supplier_id)
left outer join shippers sh on (o.ship_via = sh.shipper_id)
left outer join customers cus using (customer_id)
left outer join employees e using (employee_id)
left outer join employee_territories et using (employee_id)
left outer join territories t using (territory_id)
order by td.date_axis;
👀OJO👀 que, atendiendo al dicho “el flojo y el mezquino andan 2 veces el camino”, tuve que quitar el * y hacer la talacha de desambiguar las columnas que se llamaban igual, pero estaban en diferentes tablas, usando alias.
Esto nos crea la tabla facts_orders en PostgreSQL que luego podemos mover a MonetDB.
Noten que la tabla no tiene primary key, y esto está correcto. Ya cuando vamos a mover a MonetDB, podemos generar otra llave, o usar el campo seq_num que viene desde la tabla de dimensión de tiempo.
CREATE TABLE fact_orders (
territory_id varchar(20) NULL,
employee_id int2 NULL,
customer_id bpchar NULL,
supplier_id int2 NULL,
category_id int2 NULL,
product_id int2 NULL,
order_id int2 NULL,
date_axis date NULL,
seq_num int4 NULL,
order_date date NULL,
required_date date NULL,
shipped_date date NULL,
ship_via int2 NULL,
freight float4 NULL,
ship_name varchar(40) NULL,
ship_address varchar(60) NULL,
ship_city varchar(15) NULL,
ship_region varchar(15) NULL,
ship_postal_code varchar(10) NULL,
ship_country varchar(15) NULL,
unit_price_in_product float4 NULL,
quantity int2 NULL,
discount float4 NULL,
product_name varchar(40) NULL,
quantity_per_unit varchar(20) NULL,
unit_price_in_order float4 NULL,
units_in_stock int2 NULL,
units_on_order int2 NULL,
reorder_level int2 NULL,
discontinued int4 NULL,
category_name varchar(15) NULL,
description text NULL,
picture bytea NULL,
supplier_company_name varchar(40) NULL,
contact_name varchar(30) NULL,
contact_title varchar(30) NULL,
supplier_address varchar(60) NULL,
supplier_city varchar(15) NULL,
supplier_region varchar(15) NULL,
postal_code varchar(10) NULL,
supplier_country varchar(15) NULL,
supplier_phone varchar(24) NULL,
supplier_fax varchar(24) NULL,
homepage text NULL,
shipper_id int2 NULL,
shipper_company_name varchar(40) NULL,
phone varchar(24) NULL,
company_name varchar(40) NULL,
customer_company_name varchar(30) NULL,
customer_contact_title varchar(30) NULL,
customer_address varchar(60) NULL,
customer_city varchar(15) NULL,
customer_region varchar(15) NULL,
customer_postal_code varchar(10) NULL,
customer_country varchar(15) NULL,
customer_phone varchar(24) NULL,
customer_fax varchar(24) NULL,
last_name varchar(20) NULL,
first_name varchar(10) NULL,
title varchar(30) NULL,
title_of_courtesy varchar(25) NULL,
birth_date date NULL,
hire_date date NULL,
employee_address varchar(60) NULL,
employee_city varchar(15) NULL,
employee_region varchar(15) NULL,
employee_postal_code varchar(10) NULL,
employee_country varchar(15) NULL,
home_phone varchar(24) NULL,
"extension" varchar(4) NULL,
photo bytea NULL,
notes text NULL,
reports_to int2 NULL,
photo_path varchar(255) NULL,
territory_description bpchar NULL,
region_id int2 NULL
);
Para este efecto he creado un MonetDB en AWS con los siguientes datos de conexión:
- URL:
jdbc:monetdb://44.194.45.250:50000/northwind - user:
northwind - passwd:
northwind - database / schema:
northwind
👀OJO👀: MonetDB arranca por default con algunas propiedades, entre ellas una que se llama listenaddr, que especifica al daemon monetdbd de dónde puede escuchar conexiones. Esta propiedad solo acepta 2 valores: 0.0.0.0 para abrir el servidor al mundo, o localhost para limitarlo a conexiones locales.
Cómo sabemos esto? corriendo el comando:
$ monetdbd get all monetdb/myfarm/
property value
hostname ip-172-31-1-128
dbfarm monetdb/myfarm/
status monetdbd[2048] 11.41.11 (Jul2021-SP1) is serving this dbfarm
mserver /usr/bin/mserver5
logfile monetdb/myfarm//merovingian.log
pidfile monetdb/myfarm//merovingian.pid
sockdir /tmp
listenaddr localhost
port 50000
exittimeout 60
forward proxy
discovery true
discoveryttl 600
control no
passphrase <unknown>
snapshotdir <unknown>
snapshotcompression .tar
mapisock /tmp/.s.monetdb.50000
controlsock /tmp/.s.merovingian.50000
Para que mi MonetDB acepte conexiones del mundo entero debemos hacer:
$ monetdbd set listenaddr=0.0.0.0 monetdb/myfarm/
$ monetdbd stop monetdb/myfarm/
$ monetdbd start monetdb/myfarm/
Ahora si vamos a crear la tabla, con algunos cambios:
- La columna
"extension"que complementa elphone_numberestá entrecomillada porque en PostgreSQL esto es palabra reservada, pero en MonetDB no, por lo que vamos a quitar las comillas. - los tipos
int2eint4no existen, por lo que vamos a cambiarlos porinta secas. - el tipo
bpcharque indica texto largo igual no existe en MonetDB, por lo que vamos a cambiarlo porvarchar(250). - el tipo
float4lo cambiaremos porfloat. - el tipo
byteaes para guardar binarios. En MonetDB este tipo se llamaCLOB(Character Large Object). La columna de este tipo está pensada para guardar la foto delemployee, pero afortunadamente no tenemos ninguna, por lo que vamos a cambiarla solo para consistencia.
El create table queda así:
CREATE TABLE fact_orders (
territory_id varchar(20) NULL,
employee_id int NULL,
customer_id varchar(250) NULL,
supplier_id int NULL,
category_id int NULL,
product_id int NULL,
order_id int NULL,
date_axis date NULL,
seq_num int NULL,
order_date date NULL,
required_date date NULL,
shipped_date date NULL,
ship_via int NULL,
freight float NULL,
ship_name varchar(40) NULL,
ship_address varchar(60) NULL,
ship_city varchar(15) NULL,
ship_region varchar(15) NULL,
ship_postal_code varchar(10) NULL,
ship_country varchar(15) NULL,
unit_price_in_product float NULL,
quantity int NULL,
discount float NULL,
product_name varchar(40) NULL,
quantity_per_unit varchar(20) NULL,
unit_price_in_order float NULL,
units_in_stock int NULL,
units_on_order int NULL,
reorder_level int NULL,
discontinued int NULL,
category_name varchar(15) NULL,
description text NULL,
picture clob NULL,
supplier_company_name varchar(40) NULL,
contact_name varchar(30) NULL,
contact_title varchar(30) NULL,
supplier_address varchar(60) NULL,
supplier_city varchar(15) NULL,
supplier_region varchar(15) NULL,
postal_code varchar(10) NULL,
supplier_country varchar(15) NULL,
supplier_phone varchar(24) NULL,
supplier_fax varchar(24) NULL,
homepage text NULL,
shipper_id int NULL,
shipper_company_name varchar(40) NULL,
phone varchar(24) NULL,
company_name varchar(40) NULL,
customer_company_name varchar(30) NULL,
customer_contact_title varchar(30) NULL,
customer_address varchar(60) NULL,
customer_city varchar(15) NULL,
customer_region varchar(15) NULL,
customer_postal_code varchar(10) NULL,
customer_country varchar(15) NULL,
customer_phone varchar(24) NULL,
customer_fax varchar(24) NULL,
last_name varchar(20) NULL,
first_name varchar(10) NULL,
title varchar(30) NULL,
title_of_courtesy varchar(25) NULL,
birth_date date NULL,
hire_date date NULL,
employee_address varchar(60) NULL,
employee_city varchar(15) NULL,
employee_region varchar(15) NULL,
employee_postal_code varchar(10) NULL,
employee_country varchar(15) NULL,
home_phone varchar(24) NULL,
extension varchar(4) NULL,
photo clob NULL,
notes text NULL,
reports_to int NULL,
photo_path varchar(255) NULL,
territory_description varchar(250) NULL,
region_id int NULL
);
Ya creada la tabla vamos a hacer un ETL donde extraeremos del PostgreSQL a un CSV, y luego de ese CSV, insertaremos al MonetDB:
- La extracción del PostgreSQL:
Como tengo varias instalaciones de PostgreSQL, debo especificar el puerto donde está mi BD de Northwind:
set PGOPTIONS="--search_path=northwind"
psql -U postgres -p 5433 -c "\copy (select territory_id, employee_id, customer_id, supplier_id, category_id, product_id, order_id, date_axis, seq_num, order_date, required_date, shipped_date, ship_via, freight, ship_name, ship_address, ship_city, ship_region, ship_postal_code, ship_country, p.unit_price as unit_price_in_product, quantity, discount, product_name, quantity_per_unit, od.unit_price as unit_price_in_order, units_in_stock, units_on_order, reorder_level, discontinued, category_name, description, picture, s.company_name as supplier_company_name, s.contact_name, s.contact_title, s.address as supplier_address, s.city as supplier_city, s.region as supplier_region, s.postal_code, s.country as supplier_country, s.phone as supplier_phone, s.fax as supplier_fax, s.homepage, shipper_id, sh.company_name as shipper_company_name, sh.phone, cus.company_name, cus.contact_name as customer_company_name, cus.contact_title as customer_contact_title, cus.address as customer_address, cus.city as customer_city,cus.region as customer_region, cus.postal_code as customer_postal_code, cus.country as customer_country, cus.phone as customer_phone, cus.fax as customer_fax, e.last_name, e.first_name, e.title, e.title_of_courtesy, e.birth_date, e.hire_date, e.address as employee_address, e.city as employee_city, e.region as employee_region, e.postal_code as employee_postal_code, e.country as employee_country, e.home_phone, e.extension, e.photo, e.notes, e.reports_to, e.photo_path,t.territory_description, t.region_id from time_dimension td left outer join orders o on (td.date_axis = o.order_date) left outer join order_details od using (order_id) left outer join products p using (product_id) left outer join categories cat using (category_id) left outer join suppliers s using (supplier_id) left outer join shippers sh on (o.ship_via = sh.shipper_id) left outer join customers cus using (customer_id) left outer join employees e using (employee_id) left outer join employee_territories et using (employee_id) left outer join territories t using (territory_id) order by td.date_axis) to 'C:\Users\ramos\Downloads\northwind.csv' with csv"
Se exportaron 11876 registros.
- El import hacia MonetDB:
Dado que sacamos la big table desde nuestras máquinas locales, y mi MonetDB está remoto en AWS, vamos a tener que copiar el CSV generado a esa máquina en la nube. Esta copia la estoy haciendo con el comando de Linux scp (secure copy) porque de manera nativa en Windows, esto requeriría descargar un programita y demás.
scp -i "monetdb-key.pem" /mnt/c/Users/ramos/Downloads/northwind.csv ubuntu@ec2-44-194-45-250.compute-1.amazonaws.com:/home/ubuntu
Esto mueve nuestro CSV al home de mi máquina en AWS donde tengo el MonetDB.
Ahora entremos a la terminal de la máquina remota para importar el archivo a MonetDB. Estamos entrando con una llave privada, no con password.
ssh -i "monetdb-key.pem" ubuntu@ec2-44-194-45-250.compute-1.amazonaws.com
Convertiremos el archivo de formato Windows a formato UTF:
iconv -f cp1252 -t utf-8 < northwind.csv > northwind-formatted.csv
Ahora entraremos a MonetDB para importar el CSV:
mclient -i -u northwind -d northwind -s "copy offset 2 into fact_orders from '/home/ubuntu/northwind-formatted.csv' on client using delimiters ',' null as '';"