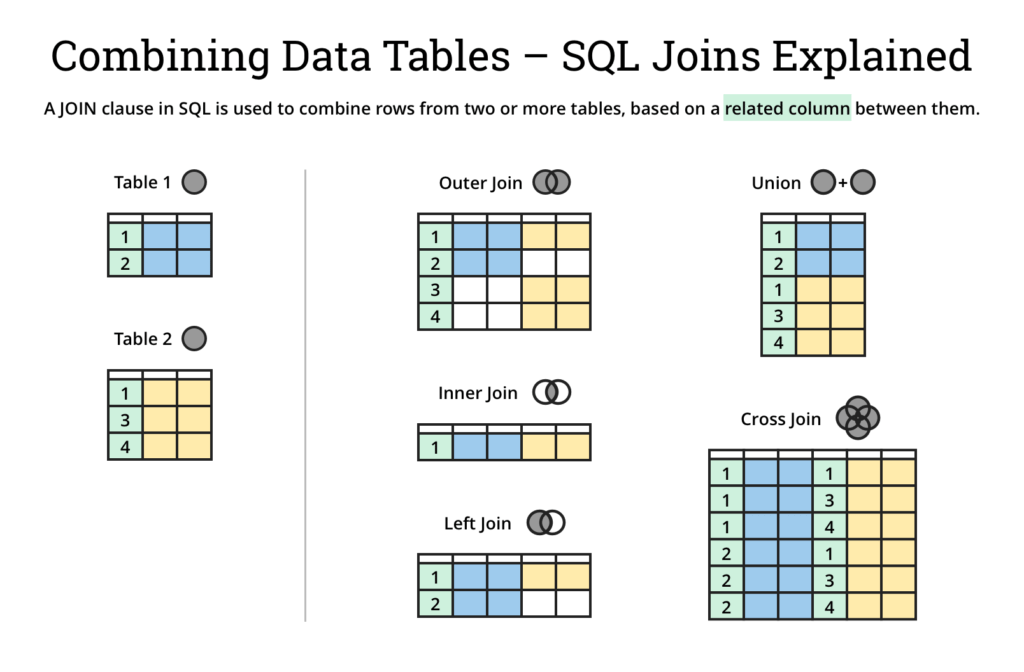
Joins
Podemos considerar los joins como un producto cartesiano con un filtro para seleccionar solo algunas de las combinaciones finales.
Veremos varios tipos de cláusulas join:
A inner join B: registros que hagan match en ambas tablasAyBA full outer join B: todos los registros de ambas tablasAyB, hagan match o noA left outer join B: todos los registros de la tablaAjunto con su match (onullsi no hay) de la tablaBA left outer join B on A.id = B.idand B.id is null: todos los registros de la tablaAjunto con su match de la tablaB
Los incisos 3 y 4 tienen su recíproco también con el caso de right join.
A inner join B
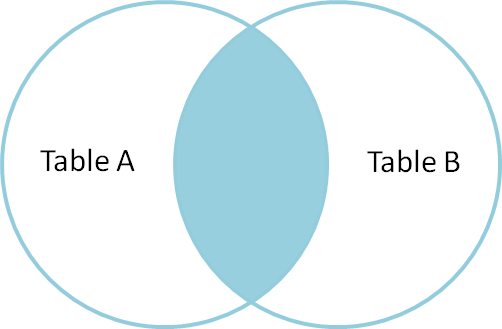
Regresa los registros de A que hacen match con B, y que ninguno de ambos son null, como se muestra aquí:

En la BD de Northwind, tenemos la relación entre las tablas customers y orders:

Si hacemos un inner join sobre customers.id_customer y orders.customer_id entre ambas, obtendremos solamente los registros de ambas tablas que hagan match en la relación.
select c.customer_id , o.order_id from customers c inner join orders o on (o.customer_id = c.customer_id);
Alternativamente, podemos quitarle el inner y solo dejar join y obtendríamos el mismo resultado.
Este es el join más natural y el que usaremos con más frecuencia.
A join B on (A.id = B.id) join C on (B.id = C.id)
Los inner join o join naturales entre > 2 tablas también nos permiten entrar por una entidad e ir recorriendo todo el modelo de datos hasta llegar al dato que queremos conocer.
Imaginemos el siguiente modelo de datos:

Si queremos responder la pregunta "qué profesores imparten clase a qué estudiantes?", podemos partir este requerimiento en otras 2 preguntas:
- "qué cursos toma cada estudiante?"
- "qué cursos imparte cada profesor?"
Y podemos responder cada una por separado:
select s.first_name, s.last_name, c.name from student s join student_course sc on (s.id = sc.student_id) join course c on (sc.course_id = c.id);select * from teacher t join course c on (t.id = c.teacher_id);
IMPORTANTE: podemos vernos tentados a responder esta pregunta en términos solamente de campos
id, pero esto realmente no sirve como entregable a quien estamos ayudando a tomar decisiones basadas en dato duro y evidencia, dado que las llaves realmente no dicen nada. Para responder esta pregunta efectivamente, debemos recurrir a atributos que identifiquen las entidades que vamos a conectar.
Como podemos ver, ya hemos hecho un join de 3 tablas para obtener los nombres de los student y sus courses, pero ahora debemos hacer un join con una 4a tabla para poder obtener los nombres de los profesores:
select s.first_name, s.last_name, c.name, t.first_name, t.last_name
from student s join student_course sc on (s.id = sc.student_id)
join course c on (sc.course_id = c.id)
join teacher t on (c.teacher_id = t.id);
Ejercicio
Pregunta: "qué nombres tienen los clientes que ordenaron productos tipo 'queso' y qué nombres de productos fueron?"\
Respuesta:
-- clientes que ordenaron productos con category = Queso
select c2.contact_name , p.product_name
from categories c join products p on c.category_id = p.category_id
join order_details od on od.product_id = p.product_id
join orders o2 on o2.order_id = od.order_id
join customers c2 on c2.customer_id = o2.customer_id
where c.description = 'Cheeses'
Normalización y utilidad de datos
Como podemos ver con estos ejercicios, para que los datos sean útiles para consumo humano, parece que debemos entregarlos desnormalizados hasta la 1NF. Es decir, nombres repetibles, renglones repetidos, etc.
Entonces, para qué invertimos tanto tiempo en el buen diseño de BDs y en normalización? No es más útil poder guardar todo justo en formato para consumo humano? Desnormalizado y sin llaves que estén aisladas del problem domain?
La respuesta es: depende. Las bases de datos relacionales que soportan sistemas transaccionales deben ser rápidas para escribir, y deben garantizar que mientras escribimos en ellas, no sucedan anomalías de insert, delete y update. Una tabla desnormalizada nos expone a tiempos de escritura más altos que unas normalizadas, y a anomalías de escritura, aunque sea más human-readable.
Estas limitantes funcionales que nos imponen las diferentes representaciones de la realidad la llamamos impedance mismatch, y en computación estamos llenas de ellas (ya hemos hablado de la impedance mismatch entre modelos ER y diagramas de clase al representar cosas como herencia y composición). En nuestro caso, representar la realidad como tablas desnormalizadas nos aumenta la utilidad de datos, pero nos expone a pronto introducir entropía en nuestro modelo al insertar nuevas observaciones o modificarla para reflejar cambios en la realidad.
Otra forma de inner join: el comando intersect
El comando intersect da como resultado algo similar a lo expresado por nuestro diagrama de Venn, sin hacer un join estructural. Chequen el siguiente query:
select c.city from customers c intersect select s.city from suppliers s;

Este query retorna las ciudades en donde tenemos tanto clientes como proveedores, y es similar a lo que regresaría el comando:
select c.city, s.city from customers c join suppliers s on c.city = s.city;

Pero dado que el comando de arriba si hace un join estructural, no solo tiene 2 columnas (1 para customers y otra para suppliers), sino que tiene renglones repetidos porque está haciendo un cross product de los campos city de ambas tablas.
A full outer join B
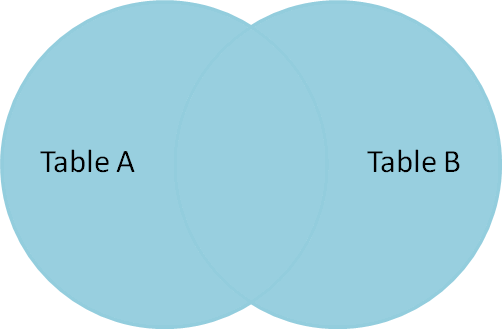
También podemos escribirlo como full join, y obtiene todos los registros de A y B, incluso los que no cumplen la relación entre ambos, dejándolos en null demambos lados en ese caso, como en la sig. figura:

Siguiendo nuestro ejemplo sobre la relación entre customers y orders, recordemos que con un join natural (o inner join) sobre la PK/FK de customer nos regresa 830 registros:
select c.customer_id , o.order_id from customers c inner join orders o on (o.customer_id = c.customer_id);

Sin embargo, si cambiamos a un full join, podemos ver que tenemos 832:
select c.customer_id , o.order_id from customers c full join orders o on (o.customer_id = c.customer_id);

Los 2 registros que aparecen ahora y que antes no teníamos son clientes que tenemos registrados, pero que no han puesto una orden nunca en su vida.
"Pa k kieres saber eso jaja saludos"
La utilidad de un full join o full outer join está en identificar las relaciones que no están ahí. A veces la falta de información es más útil que su presencia. En el ejemplo de arriba, podemos ver que los clientes PARIS y FISSA nunca nos han comprado nada. Qué podemos hacer? Descuentos exclusivos para ellos? Seguimiento? Marketing dirigido?
Finalmente, estas son las acciones que deben ser generadas con datos, y es nuestra responsabilidad como analistas de datos, administradores de BD o desarrolladores de software, empujar esta cultura en nuestras organizaciones.
Otra forma de lograr el full join sin cláusula join: el comando union
Hay otros comandos más oscuros en SQL que nos permiten lograr el mismo resultado que full join sin necesariamente utilizar la lógica de join.
Chequen el siguiente comando:
select c.contact_name, c.city from customers c UNION select s.contact_name, s.city from suppliers s;

Este comando no hace un join como tal, pero genera un resultado parecido a:
select c.contact_name, c.city, s.contact_name, s.city from customers c full outer join suppliers s on (c.contact_name = s.contact_name);
Que si hace un join estructural, como podemos verlo con los registros en null del lado de customers y del lado de suppliers.

IMPORTANTE: otro truco que acabamos de ver aquí es que podemos realizar operaciones
joinen otros campos que no sean PKs ni FKs! Esto nos ayuda bastante en cuanto a funciones analíticas porque podemos definir equivalencias sobre campos que estructuralmente no tienen nada que ver.
A left outer join B
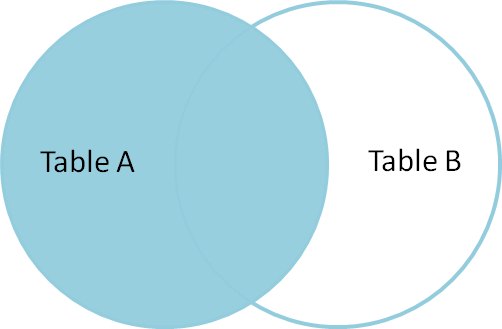
Similar al full outer join o al full join, esta cláusula regresa todos los registros de A, cumplan o no su relación con B, dejando en null aquellos en A que no tengan match, como en la siguiente figura:

En nuestra BD de Northwind tenemos un ejemplo muy claro de este uso. La tabla shippers, que contiene todas las empresas con las que podemos transportar productos, y la tabla orders, que contiene todas nuestras órdenes, tienen una relación 1 a 1, pero no todos los shippers han sido utilizados, como lo muestra esta consulta:
select s.company_name , o.order_id from shippers s left join orders o on (s.shipper_id = o.ship_via);
Cuando ejecutamos el query, vemos que:

Resulta que hemos hecho negocio consistentemente con Speedy Express, United Package y Federal Shipping, pero nunca con UPS, DHL ni Alliance Shippers.
Pensando como verdadero analista de datos (i.e. como detective), podemos generar las siguientes líneas de averiguación con esta falta de información, dependiendo de qué área lo haga:
- Tenemos convenio con estas empresas? Nos está costando? Vale la pena seguir pagando si no los hemos utilizado? (Finance)
- Hay alguien en el depto de logística que pueda estar en contubernio con estas empresas para canalizarles todo nuestro negocio? (Auditoría/Jurídico)
- Qué tipo de pricing nos ofrecen estas empresas que no hemos hecho negocio con ellas? (Logística)
- Han cambiado nuestras rutas comerciales tal que ya no hemos necesitado los servicios de estos couriers? (Operaciones)
Qué diferencia hay entre full outer/full y left outer/left?
En nuestra BD los resultados parecen ser los mismos, pero si además de tener shippers que nunca hemos usado, tuviéramos orders a las que nunca se les ha asignado el campo ship_via, entonces un full joinnos daría estos registros nulos tanto de shippers como de orders.
El que tengamos pocos de estos casos para ejemplificar habla de que la BD northwind está bien diseñada y, en la medida de lo posible, cumple con al menos la 4NF.
Y si queremos solamente los nulos?
Si modificamos nuestro ejemplo de arriba de la siguiente forma:
select s.company_name , o.order_id from shippers s left join orders o on (s.shipper_id = o.ship_via) where o.ship_via is null;
Obtenemos, solamente los shippers cuya relación con orders es nula.
Representado en diagrama de Venn, tenemos esto:
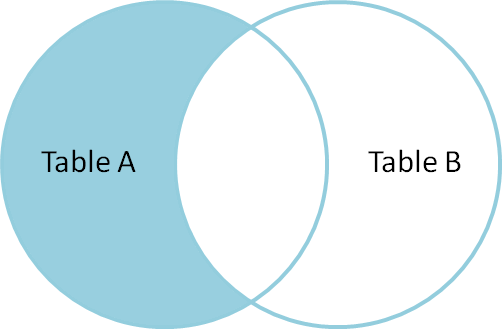
Para propósitos de las preguntas que les propongo arriba, realizar un A left outer join B con una cláusula where B.id is null nos ayuda a ser más cortos y concisos, pero igual de efectivos.
Y el right join?
Estas operaciones con left join tienen su recíproco del lado de right join, y SQL solo nos la proporciona por conveniencia y utilidad. La realidad es que utilizaremos el left join con mayor frecuencia.
Las operaciones con right join podemos representarlas con la siguiente img:

Y obviamente su recíproco en forma de diagrama de Venn:

El "anti-join"
Si el join nos da registros que cumplen una relación entre A y B, el "antijoin" nos regresa registros justamente que no cumplen la relación.
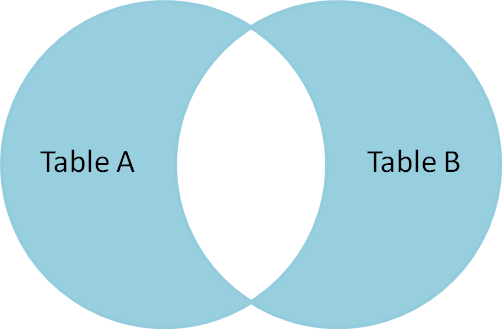
Esto se logra con un A full outer join B, pero solamente incluyendo aquellos registros donde A o B son nulos. El comando select queda así:
select * from A full outer join B on A.id = B.id where A.b_id is null or B.a_id is null
Esto nos obliga a la pregunta: cómo puede ser que hagamos join entre IDs de las tablas y luego chequemos que sean null ambas?
Como vimos arriba, podemos hacer joins entre tablas que estructuralmente no tengan relación, por lo que es perfectamente válido hacer join con, por ejemplo, nombres y checar que los IDs sean nulos, o viceversa.
No he encontrado tablas o relaciones que me permitan ilustrar el anti-join en la BD de Northwind, así que de momento esta parte tendrá que quedarse en lo teórico.
Infalible explicación visual