Transacciones
Una transacción es una estructura que permite empaquetar varios comandos de BD en una sola operación tipo all or nothing, es decir o se ejecutan todos los comandos dentro del paquete, o no se ejecuta ninguno.
Usaremos una tabla de ejemplo y la poblaremos con 1M de registros:
create table random_data (
id serial primary key, -- el tipo SERIAL reemplaza todo el merequetengue de crear una sequence y ponerle como default el nextval para esta columna :)
valor text,
fecha timestamp
);
insert into random_data (valor, fecha)
select substr(md5(random()::text), 1, 10) as valor, -- la función md5() cifra justo con el algoritmo md5 una cadena
current_timestamp - (((random() * 365) || ' days')::interval) as fecha -- crea fechas de hoy a un num de días random hasta 1 año atrás
from generate_series(1, 1000000); -- ejecuta las 2 líneas anteriores 1M de veces
Igual para esto debemos usar pgAdmin en lugar de DBeaver. Lo pueden encontrar en Windows así:
O en Mac así:

Cómo se demarca una transacción en SQL?
Demarcamos las transacciones con 3 comandos:
start transactionpara iniciar la transacción; posterior a esto usualmente incluimos el paquete comandos de escritura comoinsert,updateydelete. Algunas BDs agregan el aliasbegin transactiona este comando.commitpara escribir la transacción (y su paquete de comandos) a PostgreSQLrollbackpara reversar las operaciones que están incluídas en el paquete de transacciones que aparecen después delstart transaction
Dependiendo como nos estemos conectando a la BD, usualmente las transacciones son controladas por:
- El DBeaver
- Nuestro application code
- Manualmente con los comandos de arriba
Para esta sesión vamos a mostrar como lo hacemos con comandos y como lo hace DBeaver.
Transacciones con DBeaver
Fíjense arriba en su toolbar de DBeaver y verán esto:

Esto significa que DBeaver está en modo Auto-Commit, que significa que cada comando(s) que ejecutamos, en automático nuestro cliente los encerrará en start transaction y commit.
Para ilustrar como funcionan las transacciones, debemos ponerlo en Manual Commit, que significa que DBeaver va a guardar un transaction log de todos los comandos que meteremos, agregándole un start transaction al inicio, pero sin ningún commit al final.
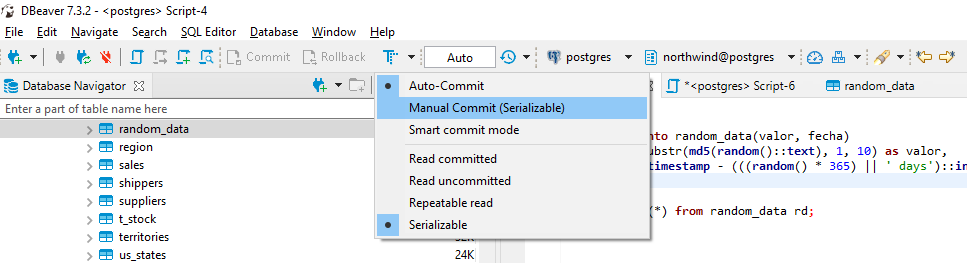
No se fijen de momento en las opciones de abajo. Son las opciones de aislamiento, y las veremos más abajo.
Ejercicio
Primero, examinemos cuantos registros tenemos:
select count(*) from random_data;
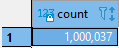
Si tengo más de 1M, es porque justo estoy ejecutando varias inserciones al desarrollar este apunte. 🤣
Vamos a insertar 5 registros en la tabla random_data en modo Manual Commit usando el comando con el que insertamos la data inicial y ejecutándolo 5 veces:
insert into random_data (valor, fecha)
select substr(md5(random()::text), 1, 10) as valor,
current_timestamp - (((random() * 365) || ' days')::interval) as fecha;
Vemos que el contador de transacciones tiene 5 statement en el transaction_log:

Examinémoslo dándole click:
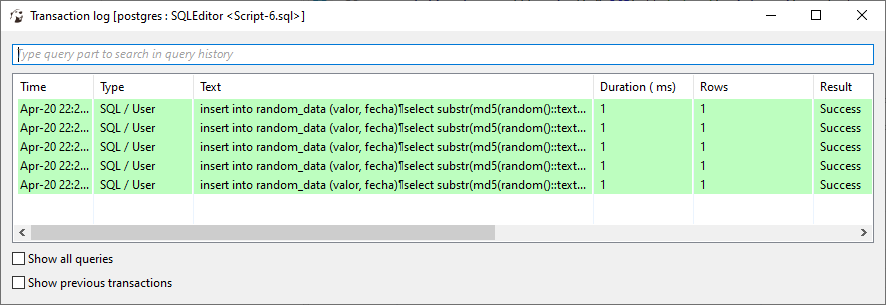
Vemos que tenemos 5 statements. Cuales son? Demos doble click en la columna Text:
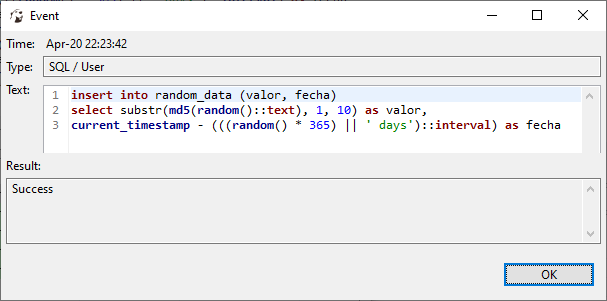
Qué hacemos ahora con estos 5 statements?
Los bajamos a la BD?
Y nos quedamos con 5 registros más?
O los reversamos?
Y nos quedamos con lo que teníamos?
Por qué no insertamos con un for?
El for no existe en SQL estándar, por lo que cada BD tiene que implementarlo ellos mismos. En el caso de PostgreSQL, todo lo que no sea SQL estándar debe estar dentro de un bloque do, como el siguiente:
do $do$
begin
for counter in 1..10 loop
insert into random_data(valor, fecha)
select substr(md5(random()::text), 1, 10) as valor,
current_timestamp - (((random() * 365) || ' days')::interval) as fecha;
perform pg_sleep(10);
end loop;
end;
$do$;
⚠️Qué estamos haciendo aquí?
do $do$: el 1erdomarca el inicio de un bloque de código, el$do$"bautiza" este bloque de código con el nombre dedobeginactúa como corchete de apertura { para agrupar códigofor counter in 1..10 loop: inicia un ciclo que irá del 1 al 10insert into random_data(valor, fecha)prepara un insert en la tabla que creamos al inicioselect substr(md5(random()::text), 1, 10) as valor, current_timestamp - (((random() * 365) || ' days')::interval) as fecha;: genera 1 renglón con datos random para insertar en la tabla que creamosperform pg_sleep(10);suspende la ejecución del ciclofordurante 10 segundos. OJO: elperformhace lo mismo que elselectPERO sin regresar ningún resultado al DBeaver y solo se puede usar dentro de bloques de códigodoend loop;cierra el ciclo for - todo lo que esté entrefor loopyend loopse va a ejecutar el num de vueltas que de el cicloend;actúa como corchete de cierre } para agrupar código$do$;finaliza el bloque de código llamadodo
Cuantos registros tenemos si ejecutamos este código en modo Manual Commit?
select count(*) from random_data;
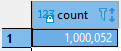
Esperen, tenemos 10 más, no?
Por qué se escribieron si no dimos click en Commit?
PostgreSQL mete cualqier bloque de código do en la transacción que se esté ejecutando en ese momento.
De hecho, si intentamos abrir transacción DENTRO del codeblock:
Vemos que no está soportado iniciar transacciones dentro de bloques de código de PostgreSQL.
do $do$
begin
start transaction;
for counter in 1..10 loop
insert into random_data(valor, fecha)
select substr(md5(random()::text), 1, 10) as valor,
current_timestamp - (((random() * 365) || ' days')::interval) as fecha;
perform pg_sleep(10);
end loop;
commit;
end;
$do$;

Vemos que no está soportado iniciar transacciones dentro de bloques de código de PostgreSQL.
Transacciones manuales
Supongamos que estamos en la chamba, que la tabla random_data tiene el histórico de casos COVID19 registrados por el INER y ejecutamos esto:
delete from random_data;
Qué tiene de malo este delete?
NO TIENE WHERE!

Este error es muy frecuente, pero estoy seguro que solo les pasará 1 sola vez en toda su vida profesional, sobre todo cuando la furia de TODA la oficina del CTO: desarrollo, infraestructura, datos, vicepresidencia de arquitectura y del CTO mismo se cierna sobre ustedes.
Por qué no les va a volver a pasar?

Las operaciones de delete y update tienen el potencial de destruir información, por lo que es recomendable que si vamos a ejecutar cualquiera de ambas, o activemos Manual Commit en DBeaver, o comencemos nuestro trabajo corriendo un start transaction:
Vayamos a pgAdmin y pongamos:
start transaction;
delete from northwind.random_data;
Hemos abierto una transacción de manera manual, y hemos borrado toda la tabla.
Pero no hemos cerrado la transacción.
Si contamos los registros de la tabla, tendremos 0. Por qué?
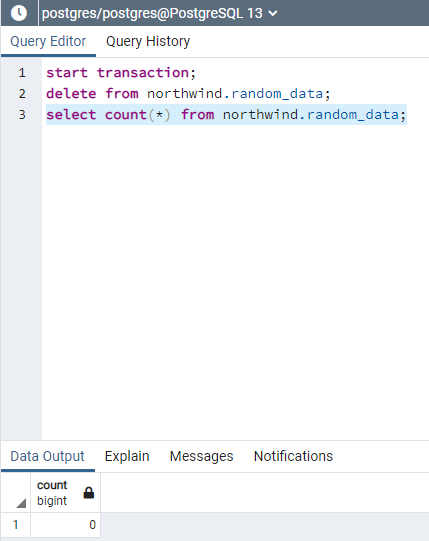
Porque este count(*) está sucediendo en la misma transacción que aún tenemos abierta.
Ok, enough fooling around. Vamos a regresar las cosas como estaban en su lugar:
rollback;
Cuántos registros tenemos ahora?
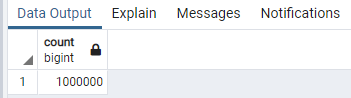
Tarea
Cuando uds compran instrumentos financieros en mercados regulados, como acciones, papel de deuda guber, divisas, metales, futuros, commodities, etc, la instrucción que giran ustedes a su institución financiera se conoce como "postura de compra". Para que su compra se de, alguien tiene que poner una postura de venta con las características suficientemente similares para poder hacerle MATCH.
El mercado es como un tanque gigante de posturas de compra y posturas de venta y un motor de matching que siempre está buscando el mejor match para una postura cualquiera.
Una vez que hay un match, entonces esa orden pasa a ejecución, pero no pasa inmediatamente. Si pasara inmediatamente, tendríamos algo como esto:
# pseudocódigo
start transaction;
ejecutar orden mercado capitales de Julieta;
commit;
start transaction;
ejecutar orden mercado divisas de Javier;
commit;
start transaction;
ejecutar orden mercado deuda de Sebas 1;
commit;
start transaction;
ejecutar orden mercado deuda de Sebas 2;
commit;
Y sabemos que esto no es muy eficiente.
Es más eficiente tener:
start transaction;
ejecutar orden mercado capitales 1;
ejecutar orden mercado capitales 2;
ejecutar orden mercado capitales 3;
commit;
start transaction;
ejecutar orden mercado deuda 1;
ejecutar orden mercado deuda 2;
ejecutar orden mercado deuda 3;
ejecutar orden mercado deuda 4;
commit;
start transaction;
ejecutar orden mercado divisas 1;
ejecutar orden mercado divisas 2;
commit;
Aún cuando dicha ejecución de ordenes esté fuera de nuestra BD
No solamente eso, sino que toda transacción de instrumentos financieros debe ir acompañado de cash. Tu institución financiera entrega tus títulos o tus CETES, y tu institución financiera debe recibir de la institución financiera contraparte una suma de cash. Solo que este cash viene de Banxico, por lo que es otro sistema externo con el que es difícil coordinar transacciones.
Suponiendo que tenemos los siguientes instrumentos:
- capitales
- deuda
- divisas
Y suponiendo que los 3 mercados los tenemos en diferentes sistemas, y que para cada sistema tenemos los siguientes verbos/funciones:
- transferir_capitales(origen, destino, monto)
- transferir_deuda(origan, destino, monto)
- transferir_divisas(origen, destino, monto)
- transferir_efectivo(origen, destino, monto)
Y que como control de flujo de nuestro programa, podemos usar las siguientes funciones de pseudocódigo:
if error thenpara verificar erroresif success thenpara verificar éxito
Y que el único que NO SOPORTA TRANSACCIONES es el de Banxico, donde se liquida la parte de cash de todas las transacciones.
Y suponiendo que en caso de error de cualquiera de estas funciones, se hace rollback de la transacción, qué secuencia de funciones hipotéticas, de control, start transaction, commit y rollback se necesitan para asegurar la ejecución all or nothing de los siguientes escenarios?
- Ulises con cuenta en GBM compra a Julieta con cuenta en Santander 400 títulos de AMZ (Amazon) a 66048.20 MXM pagaderos con cash.
- Sebas Dulong con cuenta en Citi vende a Javier Orcazas 1200 títulos de GME (GameStop) a 3714.88 pagaderos 100 títulos de deuda gubernamental con valor de 2998.12 y el restante con cash
- DJ Delgado con cuenta en Scotia vende 20000 USD a un exchange rate de 25.2 MXN y 300 títulos de deuda corporativa a un precio de 40032.71 a Frida Kaori con cuenta en Inbursa pagaderos enteramente con cash.
Valor: 2 puntos sobre final Deadline: 18 de Nov de 2021 a las 23:59:59 Formato de entrega: documento Markdown en su repo de Github
Propiedades ACID
Las propiedades ACID son exclusivas de bases de datos relacionales, y son una serie de atributos no funcionales que las vuelven confiables y una gran opción para balancear entre rapidez de escritura y de lectura.
Atomicity
Todas las operaciones en la transacción son tratadas como una unidad, y como unidad, o procede, o falla completamente.
Qué feature de la BD nos permite "atomicidad"?
Consistency
De una transacción a otra, la BD queda en estados consistentes, sin corrupción. Si la transacción falla, el
rollbackregresa la BD a su estado anterior, sin corrupción.
Ya vimos que cuando hemos hecho rollback, no reversamos parcialmente la transacción, así como cuando hacemos commit, no escribimos parcialmente la transacción.
Isolation
En esto nos vamos a enfocar hoy. Este atributo determina cómo y cuándo los resultados de una transacción son visibles a otra.
Durability
El resultado de una transacción exitosa persiste en el tiempo, aún después de una interrupción total de energía.
Ya hemos visto que cuando hacemos commit, todo se queda en la BD, y aunque apaguemos la máquina y la volvamos a prender, nuestros datos commiteados permanecerán en la BD.
Isolation a fondo
El aislamiento de una transacción controla la concurrencia. La concurrencia es como controlamos múltiples accesos de diferentes compus (o procesos de CPU) a un mismo recurso. En este caso es la BD, pero puede ser un archivo en disco, la memoria, la tarjeta gráfica, el bus USB, etc.
No controlar los accesos concurrentes puede resultar en bloopers muy chistositos que nos pueden costar muchos dolores de cabeza y desvelos, ya sea debuggeando código, o enderezando bases de datos batidas.
Concurrencia VS Paralelismo
Concurrencia es que el CPU esté atendiendo 2 tareas al mismo tiempo, dedicando todos sus recursos a una y a otra alternativamente.
Acceso concurrente es que un único recurso sea accedido por 2 o más procesos del CPU al mismo tiempo.
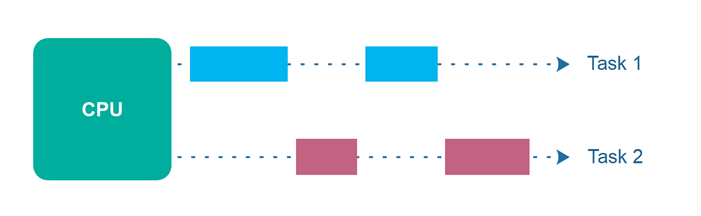
Paralelismo es que el CPU esté atendiendo 2 tareas al mismo tiempo, dedicando una fracción de recursos por completo a una, y otra fracción de recursos por completo a otra.
Qué errores tenemos si no controlamos concurrencia?
Usemos nuestra tabla random_data
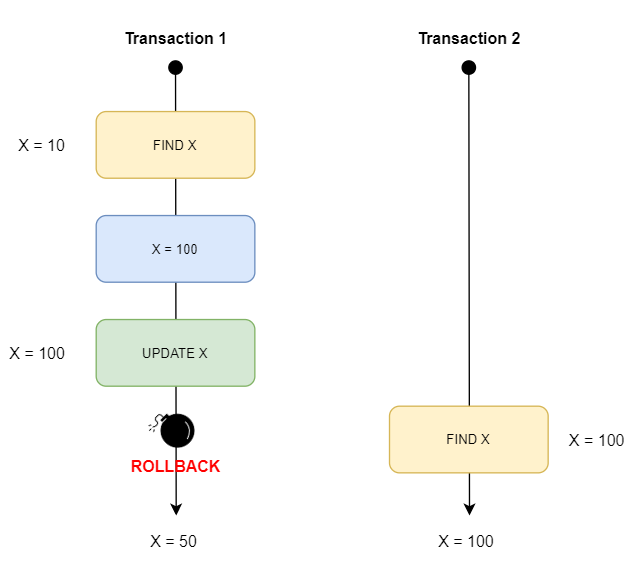
Dirty reads
- TX1: actualiza
X.valuede 50 a 100 dondeX.id = 1 - TX2: consulta
X.valuedondeX.id = 1y obtiene 100 - TX1: rollback
- TX2 se queda con
X.value = 100a pesar de que TX1 rollbackeó y dejóX.valueen 50
Afortunadamente, PostgreSQL implementa un tipo de aislamiento de transacciones que por default evitan lecturas sucias, por lo que no podremos simularlas.
| t | TX1 | TX2 |
|---|---|---|
| t1 | start transaction isolation level read uncommittedselect valor from northwind.random_data where id = 2000096; Result: '087ea30915' |
|
| t2 | start transaction;update northwind.random_data set valor = '0000000000' where id = 2000096;Result: 1 row updated |
|
| t3 | select valor from northwind.random_data where id = 2000096; Result: '087ea30915' |
|
| t4 | '087ea30915'=='087ea30915' ❌ Esperen, TX1 no debió leer el valor uncomiteado de '0000000000'? Si, pero recordemos que PostgreSQL NUNCA nos va a permitir, en ningun nivel de aislamiento, que tengamos anomalías Dirty Read. |
Qué tipos de isolation levels tenemos?
READ UNCOMMITTED: losselecten TX1 pueden ver los registros no commiteados por la TX2. Es el nivel más bajo de aislamiento y el que más problemas puede dar. ⚠️ PostgreSQL NO LO SOPORTA.READ COMMITTED: losselecten la TX1 solo pueden ver registros commiteados por la TX2 antes de que la TX1 comenzara a ejecutarse. Este es el comportamiento de PostgreSQL por default.REPEATABLE READ: losselecten la TX1 que accedan datos que están siendo alterados en una TX2 no verán las alteraciones hasta que TX1 termine y se vuelvan a acceder en una TX3.SERIALIZABLE: es el mayor nivel de bloqueo. Si una TX1 ejecuta cualquier operación en un registro, una TX2 no va a poder hacer uso de ese registro hasta que TX1 termine.
Cada uno de estos niveles de aislamiento previene los siguientes conflictos de concurrencia:
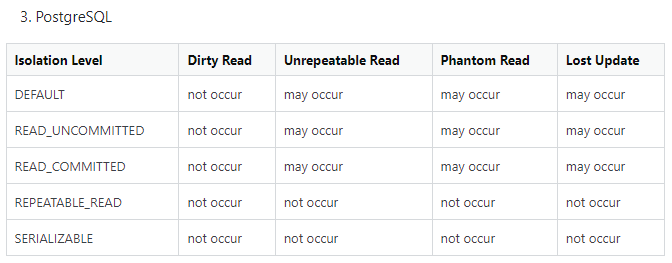
Dado que, como vimos arriba, READ UNCOMMITTED y DEFAULT (los 2 niveles más débiles de aislamiento) en PostgreSQL no está soportado, por nuestra propia seguridad, entonces no aplicarían.
Del mismo modo, la anomalía de concurrencia Dirty Read no pasa EN NINGUN NIVEL DE AISLAMIENTO de PostgreSQL, por lo que toda la columna no aplica.
Vamos a ver ahora cada anomalía de asilamiento que quedan:
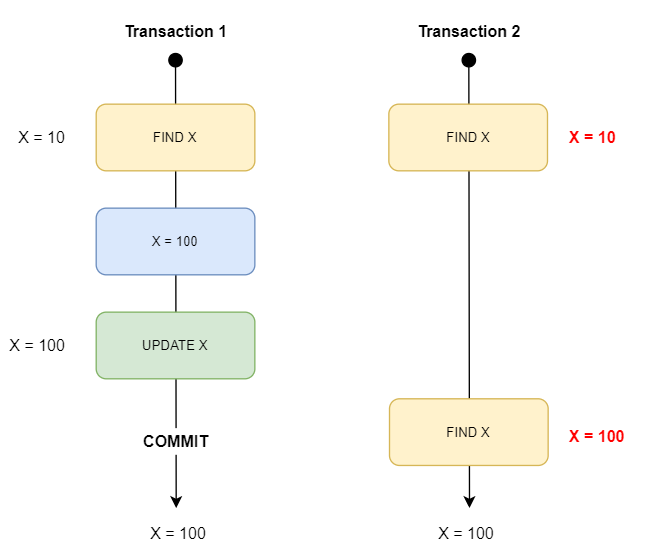
Non-repeatable Reads
- TX1: consulta
X.valuedondeX.id = 1y obtenemos 50 - TX2: actualiza
X.valuede 50 a 100 dondeX.id = 1 - TX2: commit
- TX1: consulta
X.valuedondeX.id = 1y obtenemos 100 - TX1 leyó 2 veces el registro y tuvo valores diferentes
Este escenario si lo podemos simular. Lo haremos con la tabla random_data que creamos:
| t | TX1 | TX2 |
|---|---|---|
| t1 | start transaction isolation level read committed;select valor from northwind.random_data where id = 2000096; Result: '087ea30915' |
|
| t2 | start transaction;update northwind.random_data set valor = '0000000000' where id = 2000096;Result: 1 row updated |
|
| t3 | commit; |
|
| t4 | select valor from northwind.random_data where id = 2000096; Result: '0000000000' |
|
| t5 | 087ea30915 != 0000000000 ❌ |
Como podemos ver, tenemos 2 valores diferentes para 1 misma lectura DENTRO DE LA MISMA TRANSACCIÓN.
Cómo evitamos las non-repeatable reads?
Con nivel de aislamiento REPEATABLE READ:
| t | TX1 | TX2 |
|---|---|---|
| t1 | start transaction isolation level repeatable read;select valor from northwind.random_data where id = 2000096; Result: '087ea30915' |
|
| t2 | start transaction;update northwind.random_data set valor = '0000000000' where id = 2000096;Result: 1 row updated |
|
| t3 | commit; |
|
| t4 | select valor from northwind.random_data where id = 2000096; Result: '087ea30915' |
|
| t5 | 087ea30915 == 087ea30915 ✔️ |
Con esto logramos CONSISTENCIA, aún cuando otras transacciones escriban en la misma tabla o modifiquen el mismo registro.
Phantom Reads
Esta anomalía solo sucede cuando estamos tratando con un grupo de resultados (i.e. condiciones donde el where nos regresa un resultset de varios registros), y por lo mismo generalmente los queries de agregación (i.e. sum,avg,count,max,min) son los más susceptibles a este error cuando una 2a transacción entra a hacer insert o delete.
Es similar al Repeatable Read de arriba, pero en lugar de que nos suceda con 1 registro, nos sucede con una colección de ellos, y sucede cuando:
- TX1: cuenta
X.valuedondeX.id > 1y obtenemos 50 observaciones - TX2: INSERTA en
XconX.id = 51 - TX2: commit
- TX1: cuenta
X.valuedondeX.id > 1y obtenemos 51 observaciones - TX1 leyó 2 veces el registro y aunque tenemos los mismos 50 registros, tenemos también 1 de más.
Esto es un error sobre todo al tomar decisiones de negocio como por ejemplo ejecutar select count(*) from estados_mx y siempre esperar 32 y de repente tener 33.
De acuerdo a nuestra tabla, parece que la anomalía de concurrencua Phantom Read solo puede suceder en PostgreSQL con el nivel de aislamiento READ COMMITTED, así que ese es el que vamos a usar para esta simulación:
| t | TX1 | TX2 |
|---|---|---|
| t1 | start transaction isolation level read committed;select count(*) from northwind.random_data where valor like '1234%'; Result: '45' |
|
| t2 | start transaction;insert into northwind.random_data(valor, fecha) select '1234abcd' as valor, current_timestamp - (((random() * 365) || ' days')::interval) as fecha;Result: 1 row inserted |
|
| t3 | commit; |
|
| t4 | select count(*) from northwind.random_data where valor like '1234%'; Result: '46' |
|
| t5 | 45 == 46 ❌ |
Cómo lo arreglamos?
Con nivel de aislamiento isolation level serializable, el más blindado de todos:
| t | TX1 | TX2 |
|---|---|---|
| t1 | start transaction isolation level serializable;select count(*) from northwind.random_data where valor like '1234%'; Result: '46' |
|
| t2 | start transaction;insert into northwind.random_data(valor, fecha) select '1234abcd' as valor, current_timestamp - (((random() * 365) || ' days')::interval) as fecha;Result: 1 row inserted |
|
| t3 | commit; |
|
| t4 | select count(*) from northwind.random_data where valor like '1234%'; Result: '46' |
|
| t5 | 46 == 46 ✔️ |
Serialización para bloqueo de transacciones
Para demostrar que la serialización de transacciones bloquea registros para que no entre ninguna otra a modificarlos, ejecutemos el siguiente ejemplo:
| t | TX1 | TX2 |
|---|---|---|
| t1 | start transaction isolation level serializable;update northwind.random_data set valor = '0000000000' where id = 2000096; Result: 1 row inserted |
|
| t2 | start transaction isolation level serializable;update northwind.random_data set valor = '1234abcd' where id = 2000096;... |
|
| t3 | Esperando commit o rollback |
Bloqueada hasta que se finalice TX1 |
Cuál debemos usar?
Si estamos desarrollando una aplicación, averiguemos cómo funciona el controlador de transacciones del lenguaje o librería en la que estamos implementando nuestra app y siempre usemos serializable para las que van a hacer insert, delete o update.
Si estamos realizando un análisis, o para las partes de nuestra app que van solamente a leer datos, entonces podemos protegernos aún más y usar lo siguiente:
start transaction isolation level [read committed | repeatable read | serializable] read only;
Esto pondrá la transacción en modo de solo lectura y bloqueará cualquier insert, delete o update, y nos deja solo preocuparnos por la concurrencia de lecturas en la que podamos incurrur.
Propiedades BASE
Las propiedades BASE son de las bases de datos no relacionales (MongoDB, Cassandra, MariaDB, MonetDB, etc) y relajan los criterios ACID para "apartentar" su cumplimiento en sistemas sistémicamente no críticos (usualmente los que no tienen que ver con dinero o salud, sea de personas o de todo un país).
Las siglas son:
Basically Available, Soft state, Eventual consistency.
- Basically Available: la BD está partida en N segmentos a través de sus renglones en diferentes máquinas. Si una máquina se cae, esa parte de los datos no estará disponible, pero como tal la capa de acceso a datos seguirá funcionando
- Soft state: se permiten dirty reads y phantom reads. No es fatal si suceden o si se toman decisiones con base a estas anomalías de transacciones.
- Eventual consistency: la BD no garantiza consistencia inmediata, solo garantiza su ocurrencia en un tiempo indefinido. Esto es: posteas tu foto de tu café de Starbucks en IG, pero no tienes red. IG te dice que si la posteó, pero tus amigues no la ven hasta que tienes acceso a red celular y entonces el IG de tu fono se sincroniza con tu IG en los servidores de FB
Final thoughts
Las transacciones son poderosísimas, y son piedra angular de muchos sistemas críticos. Recuerden que quien dicta si debemos alinearnos a propiedades ACID o propiedades BASE no es el sistema mismo, sino el problem domain en el que tratará de incidir. Si podemos afectar negativamente la vida de las personas, entonces mejor tratar el sistema como crítico y alinearlo a propiedades ACID. Si es algo que sistémicamente no va a impactar o el problem domain puede ser resiliente a nuestro impacto, entonces podemos alinear nuestro sistema con propiedades BASE.