Intro a Bases de Datos para Ciencia de Datos
Comenzaremos con tareas de instalación, setup y housekeeping, luego pasaremos a carga de BDs de prueba, y finalmente a discutir lo que deben ser capaces de desarrollar al final de este curso, va?
**DISCLAIMER: ** Disculpen, soy muy malhablado. Si esto les molesta, díganme con toda confianza. Nunca les faltaré al respeto, pero si le diré a villanos (como Oracle, como Palantir, como KIO Networks) por su nombre.
Documento de dudas y notas
Me he tomado la libertad de crear este documentito en Google Docs para que todos lo accedan y, si quieren, todos hacer anotaciones en él de forma colaborativa, y "arrobarme" si tienen alguna pregunta que quieran que les responda si acaso no se sienten con la confianza de levantar la mano o hacerla durante la sesión, va?
A qué le estamos tirando?
Para este ejercicio visitaremos el mapa de COVID de Johns Hopkins, y haremos un ejercicio en este pizarrón de Google Jamboard.
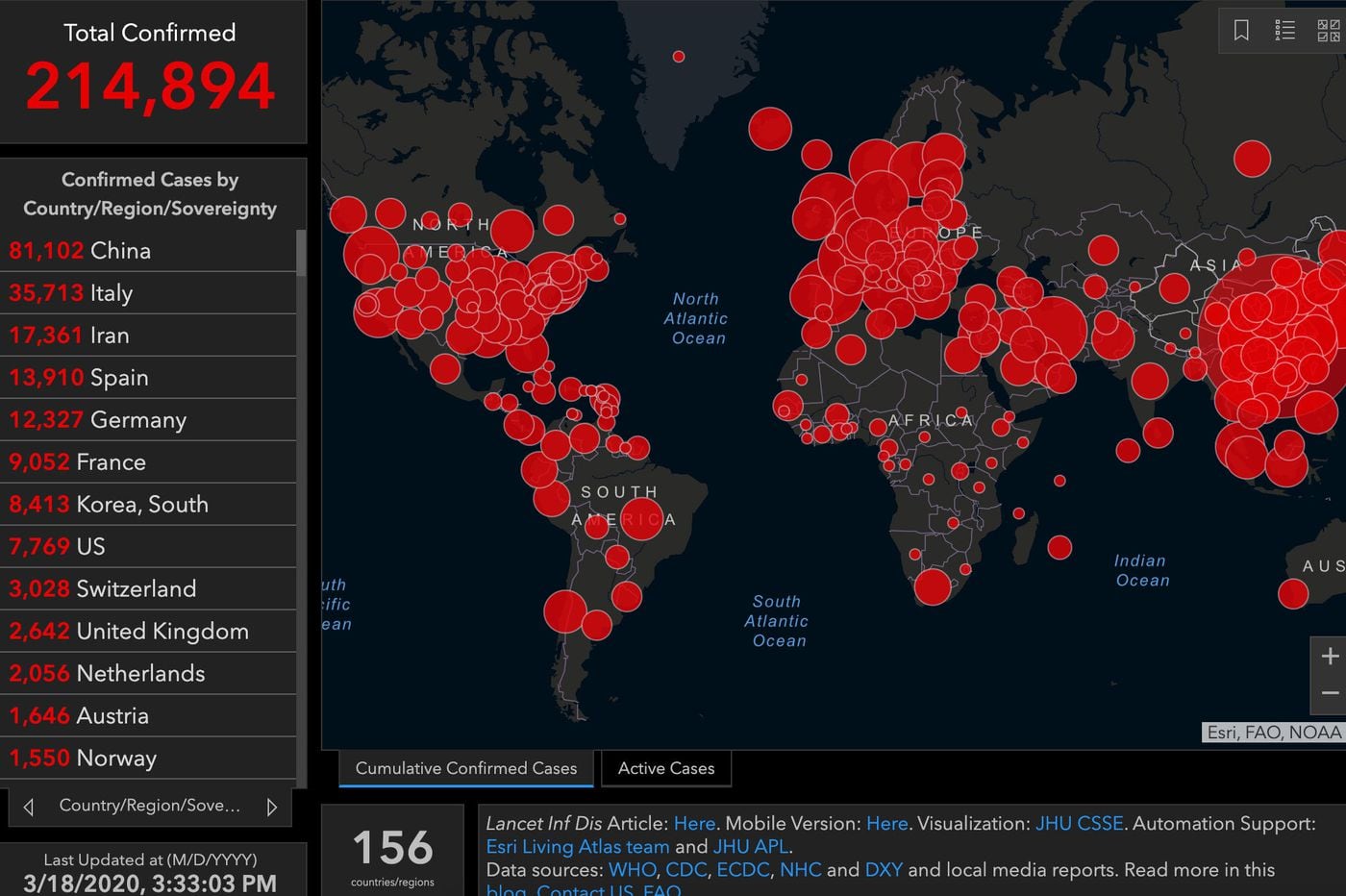
Si tomamos el mapa como un "destino final" de los datos, entonces cuál es su origen? Vamos a hipotetizar el camino que siguen:
Esquemas de diseño de BD
En esta materia trabajaremos mayormente con esquemas relacionales de BD, pero existen otros.
Esquema relacional
Este es el esquema de la BD de Sakila. Este tipo de diagramas se llaman Entidad-Relación.
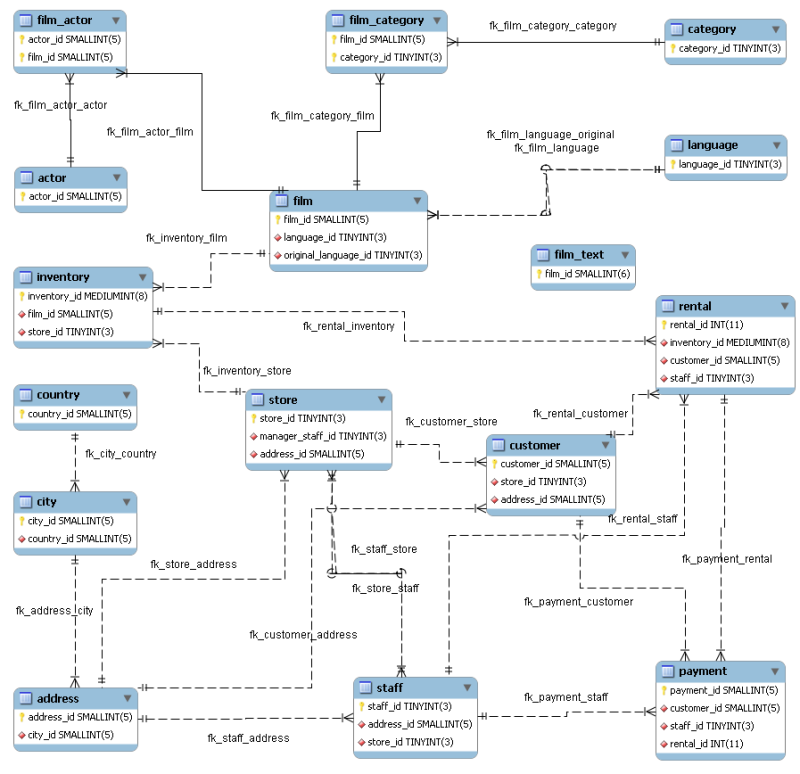
Como podemos ver, se basa en tablas y relaciones. Las tablas son entidades, las entidades tienen atributos, y algunos atributos están copiados de otras entidades: esto es lo que define una relación.
Ejemplos: Oracle, MySQL, SQL Server, H2, Derby, PostgreSQL
Esquema de red
Este es un esquema de red, que se representa con un grafo, que describe las interacciones o co-ocurrencias de una entidad, descrita por un nodo, con otra, descrita por otro nodo, y donde el grueso del edge, es decir, la conexión, representa el peso de co-ocurrencias.
Este ejemplo es de Game of Thrones.
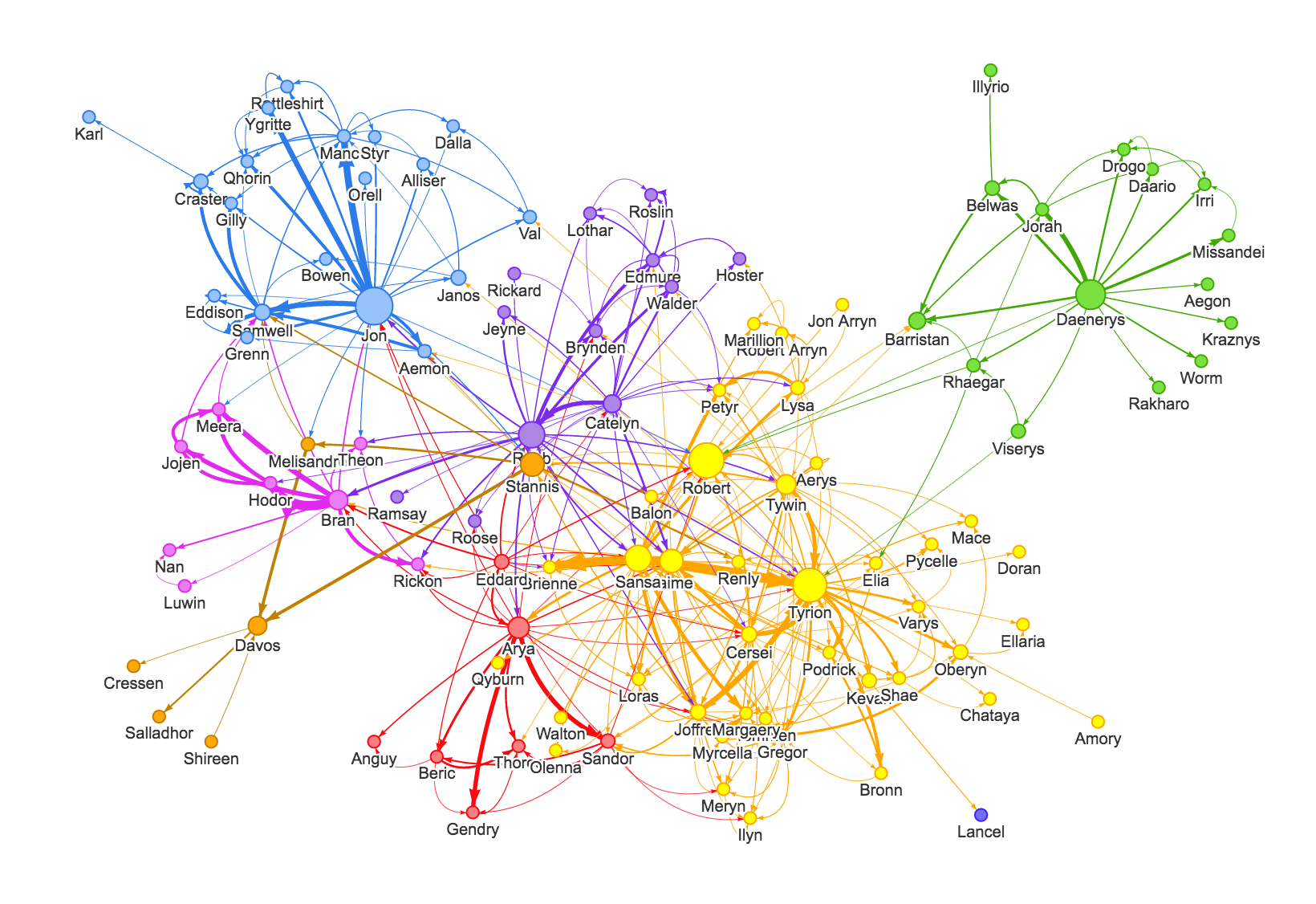
Otra métrica interesante que es fácilmente obtenible con este esquema de red es la centralidad de los nodos; osea, el num de edges que ingresan a un nodo en particular y su peso en el grafo.
Ejemplos: Neo4j
Esquema de Documentos
Este esquema es famoso para acelerar aplicaciones web debido a que están diseñadas específico para guardar JSON, que es un formato de data exchange muy usado por frameworks web actuales.
Esta es una comparación con los esquemas relacionales:

Y así es como luce un documento JSON proveniente de una webapp:

Chequen que los corchetes [] denotan una colección, los dos puntos : denotan un key a la izq y un value a la derecha, y unas llaves {} denotan un documento. Un documento puede contener otro, y éste a su vez otro, y otro, y otro, y así ad nauseam. Igual, una colección de documentos puede extenderse ad infinitum.
Ejemplos de motores de BD de documentos: MongoDB, DocumentDB, Firestore.
Take-aways
Como lo vimos durante el ejercicio, las bases de datos que cubriremos en el semestre son relacionales en cuanto a estructura, y éstas frecuentemente se denominan transaccionales en cuanto a su propósito. Estas bases de datos son muy buenas escribiendo, pero no tan buenas leyendo, sobre todo si hablamos de millones de registros. Aunque podemos usar índices y particiones para mejorar el performance de lectura en presencia de millones de registros, hay un punto de histéresis donde debemos de salir de las BD relacionales y movernos a otros tipos de storage, como BDs columnares o Big Data Stores. Una arquitectura común para un sistema de información global como el COVID Dashboard de JHU es poner una BD columnar o Big Data Store (buena para leer, no tan buena para escribir) detrás del tablero, y luego tener cientos de procesos que jalan información de cada una de los sistemas transaccionales y las bases de datos relacionales que soportan los miles de registros civiles, hospitales, y laboratorios, para luego consolidar toda esta información en un solo esquema unificado, que luego pueda ser alimentado al Big Data Store o base columnar que respalde el tablero.